
In the age of AI-assisted decision-making, ensuring fairness is more important—and more complicated—than ever. From hiring to healthcare, Machine Learning (ML) models are increasingly used to support or even make decisions that impact people’s lives. But while we’ve made progress in improving accuracy and robustness, fairness remains a persistent challenge. What does it mean for a model to be fair? Can efforts to ensure fairness unintentionally backfire?
This blog post delves into one such case, examining how a seemingly sensible fairness intervention can lead to more disparate outcomes. Specifically, we explore fairness in the context of uncertainty quantification—the way models express how unsure they are about their predictions. Instead of returning a single label, a model could produce prediction sets that contain multiple possible outcomes, offering a more nuanced view of uncertainty. While this might seem like a helpful tool for promoting fairer decisions, the reality is more complex.
To understand the fairness implications of these uncertainty-aware predictions, we examine a popular method called conformal prediction. This technique applies to any model and generates prediction sets that contain the true label with a specified probability, a guarantee called “coverage”. Prior work has proposed the fairness criterion of Equalized Coverage, ensuring that the coverage guarantee holds equally across demographic groups. However, we will see that enforcing this notion of fairness can actually exacerbate inequality in downstream decisions.
Algorithmic Fairness
Before diving into the results, let’s step back and clarify the landscape of algorithmic fairness. There are many definitions in the literature, often reflecting different intuitions and philosophical perspectives. A key axis is the distinction between procedural fairness (focused on whether the process treats individuals fairly) and substantive fairness (concerned with the fairness of the outcomes themselves).
- Procedural fairness asks: did the model follow the same rules for everyone? This includes using the same algorithmic logic and fairness criteria across groups.
- Substantive fairness asks: did the outcomes turn out fair, regardless of if the process was or was not exactly equal? For example, if one group ends up with systematically worse results, we may still have a fairness problem, even if the model treated all groups equally.
The distinction between procedural and substantive fairness is like the distinction between equality and equity. Another important distinction is between process-based metrics (like Equalized Odds or Equal Coverage) and impact-based metrics (like Disparate Impact):
- Equalized Odds ensures that error rates are equal across groups, focusing on uniform model performance as a matter of process.
- Disparate Impact focuses on the actual consequences and outcomes: does the model’s output disadvantage one group more than another, regardless of how the model makes predictions?
When should we prioritize one over the other? That depends on context. In high-stakes domains like banking, healthcare, or criminal justice, substantive fairness often takes precedence, because unequal outcomes can perpetuate or amplify societal inequalities—even if the model is formally “fair” under process-based definitions. In other settings, ensuring procedural fairness may be sufficient to build trust and accountability.
In our recent research1, we show that process-based fairness (Equalized Coverage) can actually worsen outcome-based fairness (Disparate Impact) when human decision-makers are involved. This suggests that fairness interventions must be evaluated not only in terms of their technical definitions, but also in terms of how they influence real-world outcomes.
Rethinking Fairness in Conformal Prediction
Uncertainty is an unavoidable part of ML. When models make predictions, there is always some uncertainty — but how do we communicate this uncertainty in a way that leads to more fair decisions? Conformal Prediction (CP) offers a promising approach by providing prediction sets instead of single-point predictions, ensuring that the true outcome is captured with a specified probability.
The core idea is to assign a nonconformity score to each possible label for a new example—this score reflects how unusual that label would be if it were correct. Then, using calibration data, marginal CP constructs a prediction set by including all labels whose nonconformity scores are not too extreme, ensuring that the set contains the true label with high probability (e.g., 90%). The size of the set communicates uncertainty—when the model is more uncertain, it needs to give more alternatives to ensure the correct answer is included. Notably, the coverage guarantee holds without assumptions on the model’s accuracy or structure, making conformal prediction a powerful, model-agnostic tool for reliable uncertainty quantification.
Read an introduction to conformal prediction here
When CP sets are used to support real-world decisions, fairness concerns can emerge. Although CP guarantees that the true label is included in the prediction set with high probability on average—say, 90%—this guarantee holds marginally, across the entire population. When the data is divided into groups, some groups may receive more than 90% coverage, while others receive less. This imbalance can lead to systematic disparities, raising concerns about fairness in practice, especially when groups are based on sensitive attributes like gender or age.
From the procedural fairness point of view, a natural requirement is then to ensure that coverage is equal across different groups — this is the principle behind Equalized Coverage.2 The idea is that no group should systematically receive less reliable predictions than another.
When Prediction Sets Meet Decision-Making
In many AI-driven applications — medical diagnosis, hiring, or loan approvals for example — simply providing a set of possible predictions is not enough.
Consider a loan approval system that classifies applicants into one of several categories: approve with low interest, approve with standard interest, approve with high interest, manual review, or reject. This is a multiclass prediction problem where only one option can be acted on. A CP system would provide a set of plausible outcomes for each applicant, such as {approve with low interest, manual review} or {reject, manual review, approve with high interest}. A human or automated system must ultimately make a decision on what action to take based on these sets.
Suppose now that the system consistently returns larger sets (e.g., including more costly or ambiguous options) for applicants from certain demographic groups, reflecting higher uncertainty. While the true outcome may still be included in the set, decision-makers might interpret these broader sets as riskier cases. This could lead to those groups receiving higher interest rates, being flagged more often for manual review, or being rejected more frequently—all unintended consequences of how uncertainty is communicated.
Ideally, decisions should be fair across different demographic groups. If one group consistently receives larger prediction sets than another, this can translate into unequal treatment, affecting opportunities and outcomes.
Nevertheless, it has been shown that conformal sets improve human decision-making.34
The question now is: is the benefit shared equally across all groups in the data?
Fairness in Conformal Prediction: The Pitfall
Coverage alone does not tell the full story. Our research shows that even when coverage is equalized, the size of prediction sets can still vary significantly between groups in practice. This can lead to disparate impact: if one group consistently receives larger sets, decision-makers can and do struggle more to act on those predictions, leading to biased or unfair outcomes.
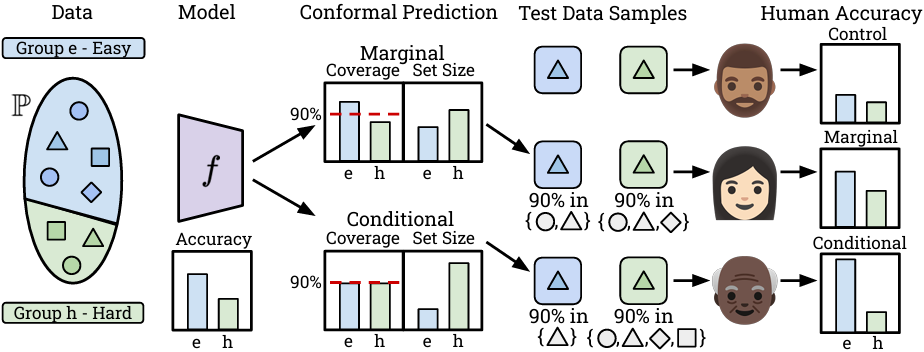
Given a data distribution \(\mathbb{P}\) with groups of differing difficulty, a model \(f\) may have inherent bias. Using marginal CP can translate to lower coverage and larger sets for the harder group. Conditional CP (i.e., with Equalized Coverage) must increase set sizes on the harder class, and reduce them on the easier class.
The Surprising Finding: When Equalized Coverage Increases Disparate Impact
We conducted experiments with 600 human participants across 3 independent tasks with different modalities to analyze how prediction sets influence decision-making:
- FACET – Image Classification. Groups: Age of subject
- BiosBias – Text Classification. Groups: Gender (M/F) of biography subject
- RAVDESS – Audio Emotion Recognition. Groups: Gender (M/F) of speaker

We proposed two hypotheses on the impact of CP sets as a decision aid:
Hypothesis 1 – Prediction sets given to human decision-makers can cause disparate impact on their performance.
Hypothesis 2 – Sets with Equalized Coverage will cause greater disparate impact than marginal coverage.
We measured the increase in human accuracy when prediction sets are provided, compared to no model assistance, on a per-group basis. Let
\begin{equation}
\delta_a = \mathrm{acc}_{\mathrm{sets}}[x \mid g(x) = a]\ – \ \mathrm{acc}_{\mathrm{control}}[x \mid g(x) = a],
\tag{1}
\end{equation}
be the difference between the human accuracy for examples \(x\) from group \(a\) when prediction sets are provided, and the human accuracy for the same examples when there was no model assistance (i.e., control group). We define the accuracy Disparate Impact (DI) as follows: considering every pair of groups \((a,b) \in \mathcal{G} \), let
\begin{equation}
\Delta := \mathrm{max}_{a,b \in \mathcal{G}} (\delta_a-\delta_b).
\tag{2}
\end{equation}
Accuracy Disparate Impact occurs when \(\Delta\) is non-zero.

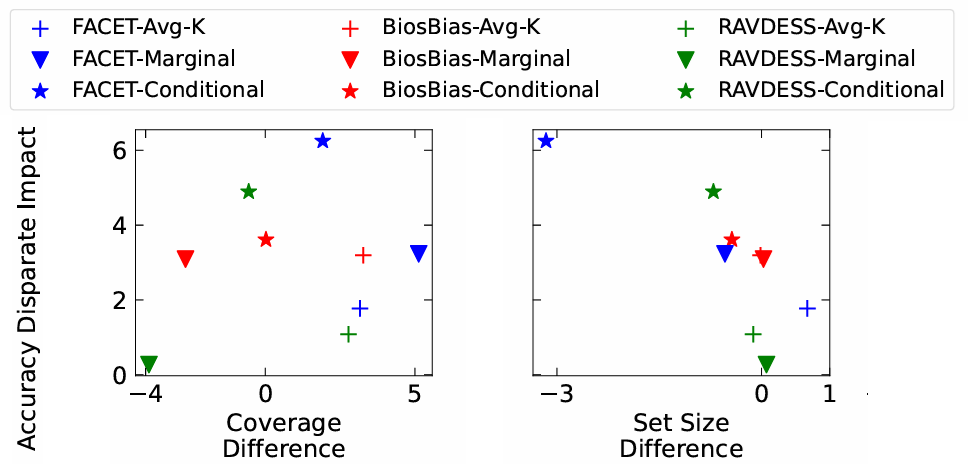
The main quantitative results of our experiments are shown in the above Figure, where we see that marginal CP sets can cause DI, but conditional sets (i.e., with Equalized Coverage) cause significantly more. As a benchmark, we include results from the Average-k method (Avg-k)—a non-conformal approach that selects prediction sets based on a fixed average size.
We found that enforcing Equalized Coverage did not improve fairness — it actually increased DI in the final decisions. One potential explanation is that when one group systematically receives larger prediction sets, decision-makers face more ambiguity and may resort to biased heuristics when making choices.
For full details on our statistical analysis and conclusions, read the full version of our paper.
A Better Alternative: Equalizing Set Sizes for Fairer Outcomes
In our experiments, when the set sizes across groups were more equal, we observed more fair outcomes. As we can see in the Figure below, we found that DI correlates strongly with set size differences between groups, not coverage differences. Instead of focusing on Equalized Coverage, we propose a new fairness criterion: Equalized Set Size. By ensuring that all groups receive prediction sets of roughly the same size, we expect a reduction in Disparate Impact. This approach provides a more intuitive and actionable notion of fairness.
Rethinking Fairness in AI Systems
Our findings challenge the conventional wisdom around fairness in conformal prediction. They suggest that fairness interventions must consider not just mathematical guarantees but also the real-world implications of how predictions are used. In many AI applications, fairness should be evaluated at the decision-making stage, not just in the model’s outputs. As machine learning systems continue to be deployed in high-stakes settings, ensuring they lead to equitable outcomes remains an open challenge — one that requires both theoretical rigor and empirical validation.
Our work provides a step in this direction, but many questions remain. How should fairness be defined when humans interact with AI-generated uncertainty? What other unintended consequences might arise from well-intentioned fairness interventions? As the field of algorithmic fairness evolves, these are the questions we must continue to explore.
References
- Cresswell, Kumar, Sui, Belbahri. “Conformal prediction sets can cause disparate impact” ICLR 2025 ↩︎
- Romano, Foygel Barber, Sabatti, Candés. “With Malice Toward None: Assessing Uncertainty via Equalized Coverage” HDSR 2020 ↩︎
- Cresswell, Sui, Kumar, Vouitsis. “Conformal prediction sets improve human decision making” ICML 2024 ↩︎
- Cresswell. “Improving Trustworthiness of AI through Conformal Prediction” Layer6 AI at TD Blog 2024. ↩︎


