This post is about our paper entitled “Trustworthy AI Must Account for Interactions” presented at the ICLR 2025 Workshop on Bi-directional Human-AI Alignment. Please refer to the full paper for complete details.
How to Build Trust into AI
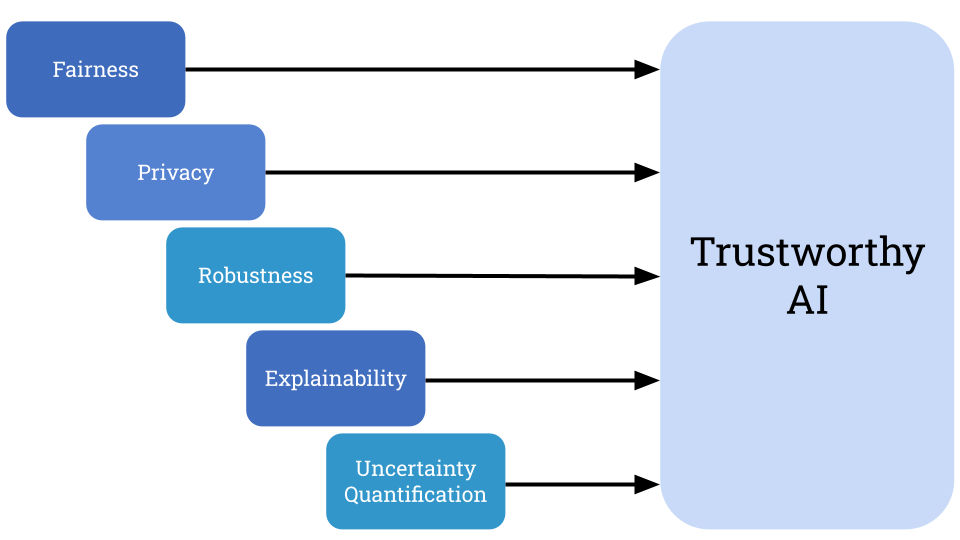
Artificial intelligence (AI) systems have become widespread as consumer tools for productivity, and increasingly as autonomous agents that can interact with our digital world. It is incredibly important that these tools are built to be aligned with human values, which is the overall goal of the field of research known as Trustworthy AI (TAI). Chief among the tenets of TAI are fairness, privacy, robustness, explainability, and uncertainty quantification — each of which is a noble pursuit, but all of which must be harmonized to promote deep trust. The ultimate goal of TAI is to achieve these aspects simultaneously.

Luckily, there are many techniques for improving each of these aspects individually, and incorporating them into the AI development workflow. This suggests a simple path to achieving trust: find technical solutions to improve each aspect, and implement the solutions one after another.
However, this simple path turns out to be deceptively problematic because techniques for improving a given TAI aspect often harm others. For example, applying training methods to improve privacy can amplify biases in the data as a side effect, undermining fairness. While not always acknowledged, these unintended interactions are very common — we give many examples below. As a result, the straightforward approach of addressing TAI aspects one-by-one ultimately undermines trust rather than reinforcing it.
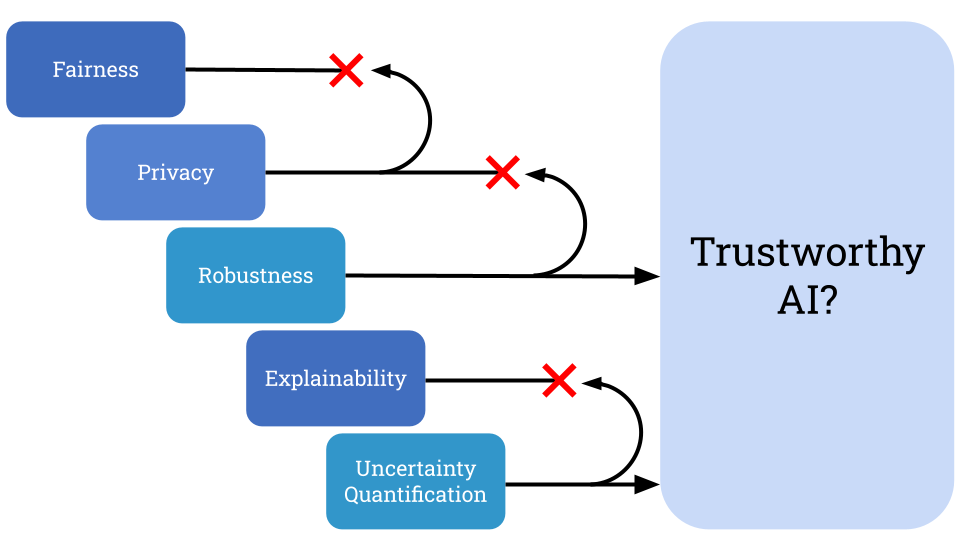
Much of today’s research into TAI focuses exclusively on one or two aspects of trust at a time, not directly on the overall goal of achieving many aspects simultaneously. Although there are documented cases where negative interactions occur between TAI aspects, because the field spans so many sub-topics, the extent and prevalence of negative interactions has not been fully realized by the community. This raises the question: If solutions to individual aspects tend to not play nice with each other, what will it take to build trustworthy AI models in practice?
In this post, we demonstrate practical steps that researchers and practitioners can take to build holistic trust in AI, avoiding the pitfalls of negative interactions. Before getting there, we review five of the most important aspects of trust and enumerate the interactions that can occur between them. This review is intentionally limited in scope — we only consider a narrow subset of topics within each aspect. Nevertheless, within this narrow subset it is still easy to stumble into negative interactions, which indicates just how common they are.
Trustworthy AI Aspects
Fairness
Fairness is a nuanced and highly contextual topic — it cannot be boiled down into a single set of guidelines to follow in all cases. Instead, we must consider each circumstance on its own to determine the appropriate approach.
Let’s take the case where individuals belong to groups (e.g. genders). A model may or may not have access to this group information. Without group labels (or other features that could be proxies), a model cannot treat individuals differently based on that information. However, treating people equally isn’t always enough, because every individual comes from a different background with a different status. Hence, fairness often seeks equity — that all subjects receive comparable outcomes. For this, a model may actually use group information to influence its predictions on a case-by-case basis so that it can avoid Disparate Impact where some groups would be affected more than others. Disparate Impact can be measured in terms of the target outcome of the model. For instance, if the model’s predictions are supposed to be highly accurate for all groups, we can measure the accuracy disparity which is the largest difference in accuracy between any two groups in the data.
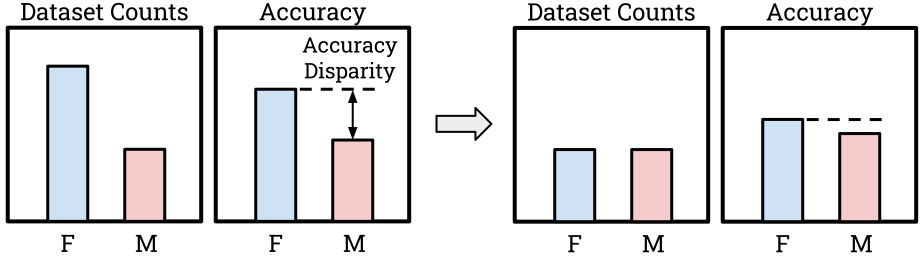
Minimizing Disparate Impact can be pursued at several stages of modelling though fairness interventions, including pre-processing (e.g. balancing data across groups before training), in-processing (e.g. adding fairness regularization terms to the loss function), or post-processing (e.g. using model scores differently across groups when making decisions).
Read this blog to learn more about fairness in machine learning
Privacy
Privacy has become a crucial area of research in TAI as models increasingly use personal information for training, leading to growing concerns about privacy breaches and unauthorized data access. In ML, privacy concerns are usually demonstrated adversarially, where an attacker tries to extract as much information as possible from the model’s training set. The standard example is a membership inference attack (MIA) in which the attacker tries to determine if a test datapoint was part of the model’s training dataset.
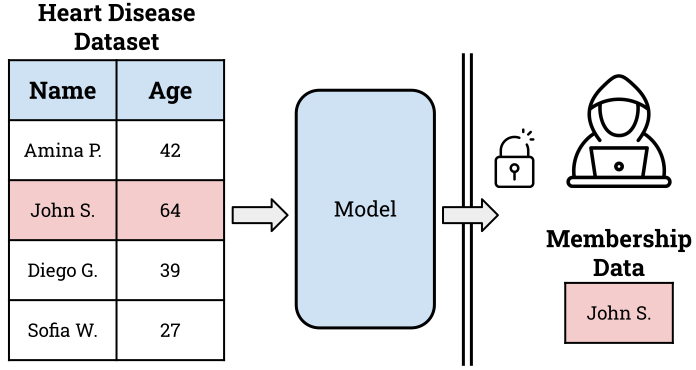
An unsuccessful MIA does not indicate the system is safe; there could always exist a stronger attack that would succeed. Hence, privacy researchers rely on a mathematical framework, Differential privacy (DP), that quantifies how much information could be exposed by an ML model in the worst case. By carefully injecting noise into how data is processed, DP covers up the effect of any one datapoint making it harder to successfully perform MIAs. For an ML model, practitioners typically add noise during training directly to the gradient updates. This method, called DP-SGD, first computes per-sample gradients and clips large values, aggregates samples together, then adds noise before using the gradient to update the model. The resulting model weights have been privatized and contain a quantifiably small amount of information about any given training datapoint.
Robustness
Robustness broadly refers to the ability of a model to maintain its performance and reliability under a variety of conditions. Like privacy, robustness can be tested adversarially — an attacker actively tries to produce unintended behaviour by perturbing the input of a model, often in ways that are imperceptible to humans. Adversarial examples are inputs that the model gets wrong but are very close to ordinary examples that the model is actually successful on. They can be created by maximizing the model’s loss on the correct answer rather than minimizing.
The most common way to defend against adversarial attacks is by exposing the model to adversarial examples during training. Along with regular datapoints from the training dataset, the model is shown adversarial versions and is trained to give consistent answers.

Explainability
Explainability enables researchers and practitioners to understand, validate, and trust decisions made by complex models, while also giving the ability to audit those decisions retroactively. Without explainability, models can behave like a black box, leading to unjustified outcomes that are difficult to detect or correct. Some ML models, such as shallow decision trees and linear regression, are inherently more interpretable than others, like deep neural networks. Regardless, in regulated industries explainability is a requirement, not just a good practice. All models must come with local explanations that shed light on individual predictions, giving users a way to understand why a decision was made.
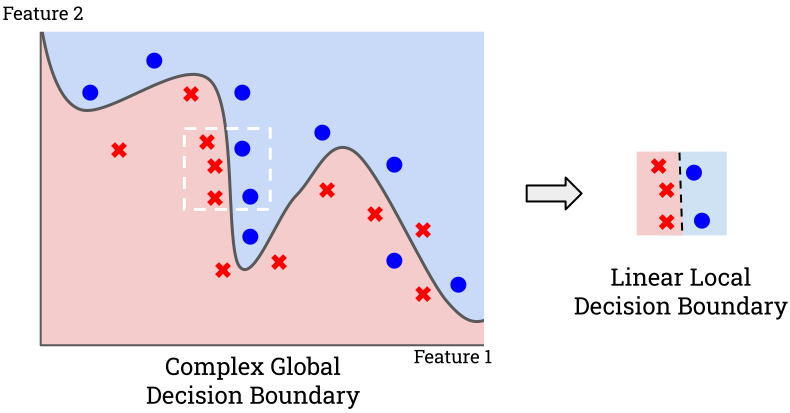
Local explanation methods are often designed to be model-agnostic and feature-based so that they can apply across different ML algorithms. These methods interpret behavior by analyzing the importance of input features for a given prediction. One popular method is Local Interpretable Model-agnostic Explanations (LIME) which aims to provide explanations that preserve local fidelity — that the explanations correspond to the model’s actual behaviour. LIME’s explanations take the form of a sparse linear model which approximates the complex model around the input datapoint. The weights of the linear model communicate how important each corresponding feature is.
Uncertainty Quantification
Typical ML models are not designed to express confidence in their predictions. Quantifying uncertainty helps make models more trustworthy, as the user can judge when to ignore the model in favor of alternatives. One increasingly popular method is conformal prediction (CP), which changes models to output sets of predictions (e.g. several class labels) where larger sets indicate greater uncertainty. Notably, CP provides a coverage guarantee that the true label will be in the set with high probability, like 90%, which the developer can set based on their risk tolerance. For equal coverage levels, smaller average set sizes are more useful and indicate more confident predictions.

To learn more about conformal prediction, read our previous blog post
Negative Interactions Between Trustworthy AI Aspects
To demonstrate the point that achieving trust requires a holistic approach, not considering aspects one-by-one, we give examples of how the technical solutions reviewed above can unintentionally harm other aspects. We argue that negative interactions are commonplace, not the exception, and consider representative combinations of our five main aspects of fairness, privacy, robustness, explainability, and uncertainty quantification. However, examples of negative interactions are not limited to the ones we discuss here. In fact, there are examples for every pairwise combination of these five aspects, and in both directions! For an exhaustive discussion including citations to the original sources that uncovered these interactions, please see our accompanying research paper.
For two TAI aspects A and B, we use the shorthand A → B to indicate that applying a solution for A has a negative impact on B.
Fairness 📈 → Privacy 📉: At the most basic level, evaluating or correcting the fairness of every ML model necessitates collecting information on group identifiers, like age, gender, or race. Collecting, storing, and using this information for fairness purposes exposes individuals to greater risk of data leaks. One of the primary purposes of fairness interventions in ML is to increase the model’s focus on underrepresented groups. While this can improve accuracy on those groups, the increased influence also leads to memorization of datapoints, exposing them to greater privacy risks.
Privacy 📈 → Fairness 📉: While DP-SGD is the de facto standard method for achieving privacy guarantees on ML models, it is well known to cause Disparate Impact by increasing accuracy disparity. In ordinary SGD, datapoints from an underrepresented group have higher loss, and hence larger gradients, which increases their relative influence on the optimization to naturally balance the model’s performance. In DP-SGD large gradients are clipped, making them relatively less influential on the optimization process, causing underrepresented groups to be “ignored”.
Fairness 📈 → Robustness 📉: When groups in the dataset are underrepresented, fairness interventions to reduce model bias can increase the relative influence of those groups. Like with privacy risks, this increased influence can make the very same groups more susceptible to adversarial attacks. Fairness interventions can reduce the average distance from training samples to the decision boundary, which makes it easier to find adversarial examples — nearby datapoints that are on the other side of the boundary.
Uncertainty Quantification 📈 → Fairness 📉: Conformal prediction sets are used as a form of model assistance for human decision makers, and it has been found that humans have higher accuracy on tasks when given smaller prediction sets. Average set sizes typically vary between groups, meaning that human accuracy improves more for some groups than others, another example of Disparate Impact.
Privacy 📈 → Robustness 📉: Models trained with DP-SGD tend to be less adversarially robust than the same models trained with ordinary SGD. The clipping and noise addition steps in DP-SGD slow the convergence of models giving decision boundaries that are less smooth. Bumpy boundaries make it easier to identify directions in the input space where small perturbations can flip the model’s prediction to an incorrect label.
Explainability 📈 → Privacy 📉: When provided in addition to the model’s output, local explanations expose another avenue for private information to be leaked. Explanations are designed to reveal details about how specific inputs influence model predictions, so it is unsurprising that they can be exploited to make MIAs more effective. Explanations about a datapoint generated by LIME consist of a sparse linear model whose behaviour will vary depending on whether the datapoint was included in the training set or not, which directly gives attackers an angle for more effective MIAs.
Robustness 📈 → Explainability 📉: Adversarial training fundamentally alters the feature representations that are learned by the model, changing its behaviour. Since adversarial training introduces synthetically altered training datapoints, the learned representations can be unnatural, leading to unexplainable behaviours and reduced explanation fidelity.
Explainability 📈 → Robustness 📉: Feature-based explanations like LIME are susceptible to adversarial perturbations which do not change the model’s prediction but greatly change the explanation. For any given prediction, users may expect there to be a single explanation, and hence non-robust explanations cast doubt on the reliability of all explanations.
Privacy 📈 → Uncertainty Quantification 📉: Conformal prediction could be applied to any model trained with DP-SGD without affecting the privacy of the training dataset. However, the quality of UQ with a differentially private model will suffer compared to a non-private model. The per-example clipping used in DP-SGD causes miscalibration, which affects the utility of CP by increasing the size of prediction sets.
Explainability 📈 → Uncertainty Quantification 📉: LIME generates local explanations for a given datapoint by evaluating the model on slightly perturbed versions of that datapoint, created by adding small amounts of random noise. Researchers have found that LIME’s explanations are highly sensitive to both the specific noise added and the number of perturbed samples used. These factors can lead to significant variations in the rank order of important features, indicating a considerable degree of uncertainty in LIME’s explanations that is often overlooked.
These ten examples are representative of what can happen when applying any technical solution designed to improve trust for one aspect in isolation. In the following section, we discuss how practitioners can account for interactions like these with a holistic approach to TAI.
Trustworthy AI Must Account for Interactions
The overall goal of Trustworthy AI research is to enable not one or two aspects of trust, but many simultaneously. Current research in TAI very commonly follows the same formula: one or two TAI aspects are selected, then technical solutions are developed and evaluated to show improvement on the selected aspects. Possible interactions with aspects outside the ones selected are rarely considered. The most straightforward attempt to achieve the overall goal of trust would be to overlay several technical solutions. However, the examples from the previous section demonstrate that negative interactions between TAI aspects are quite common. Based on these observations our opinion is that combining solutions to individual TAI aspects will not resolve the trust and alignment problems facing AI. Trustworthiness is not achieved by overlaying isolated technical solutions but emerges from integrating TAI aspects within a holistic framework that accounts for interactions.
Trustworthy AI should consider all relevant aspects simultaneously, not in a sequential or siloed manner. It relies on interdisciplinary expertise from ethicists, legal experts, and of course computer scientists, to bring together knowledge from disparate fields. It is context-aware and adapted to its deployment domain, taking account of specific requirements — like the primacy of patient safety in healthcare. Trust in AI systems will be achieved not solely through technical solutions, but by aligning AI with societal needs, and recognizing real-world constraints.
To advance Trustworthy AI, we provide guidance to practitioners on how to achieve it in practice, acknowledging the likelihood of negative interactions, trade-offs, and challenges from combining many objectives.
- Prior to model development, enumerate all relevant TAI aspects and prioritize them by importance in the application at hand. Involve stakeholders including model developers, users, and subjects.
With so many desirable objectives, it may not be possible to achieve them all simultaneously to the same extent. However, some aspects are likely to be more critical than others in any given context. Hence, deliberate relevancy ranking will help to establish clear priorities for which aspects cannot be compromised on. - Establish clear metrics and develop automated tests for each relevant aspect when possible but also recognize soft goals and constraints within the deployment context.
Progress towards a goal cannot be measured without clear metrics. If the goal is to improve fairness, privacy, or any other aspect, it is crucial to decide on the appropriate metrics before development begins. Not only can metrics indicate improvements, but just as importantly they will indicate when issues begin to arise, for example from negative interactions. Automated testing removes selection bias (i.e. only running tests where and when improvements are anticipated) which helps ensure negative effects are caught. - Deliberately analyze how TAI aspects could interact, positively and negatively, before implementing technical solutions or optimizing for metrics.
We have argued that negative interactions are commonplace. Despite one’s best intentions, applying a new technique to improve some aspect of trust can erode progress in other areas. Many such interactions have been documented (see our complete review in the full paper) and hence can be identified ahead of time. - Evaluate the potential risks of negative interactions by quantifying their likelihood and severity.
Not all negative interactions are necessarily an issue. If the measured impacts are small, the benefits to some aspects may outweigh the negatives to others. By taking a prudent and quantitative risk management approach, the most probable and severe issues can be given the most attention. - When applying technical solutions to improve any single aspect, perform ablations to measure impact on all other aspects, not just accuracy.
Failing to notice when a negative interaction has occurred is the most likely way to unintentionally cause harm. Measuring only one or a few aspects of a model’s performance hinders the ability to identify relapses in some dimension. The use of automated testing on every change greatly helps in this regard. - When negative interactions or trade-offs are observed, assess the impacts to each aspect and manage compromises according to the pre-established priorities.
Again, it may not be possible in all contexts to improve all relevant aspects of trust simultaneously, leading to the need for compromise. In the face of negative interactions, referring back to the pre-established priorities, estimation of risk severity, and quantitative metrics will help to unblock AI deployments and understand the limitations of a system.
These steps will help to develop a risk-based prioritization of TAI aspects and balance competing constraints, enabling users to proactively anticipate, measure, and mitigate negative interactions. Still, achieving multi-faceted trust is not a solved problem. We call for TAI researchers to broaden the scope of their work beyond one or two aspects in isolation, and work towards a holistic model of trust combining many aspects while accounting for interactions.