A control-oriented framework for practical, sustainable unlearning
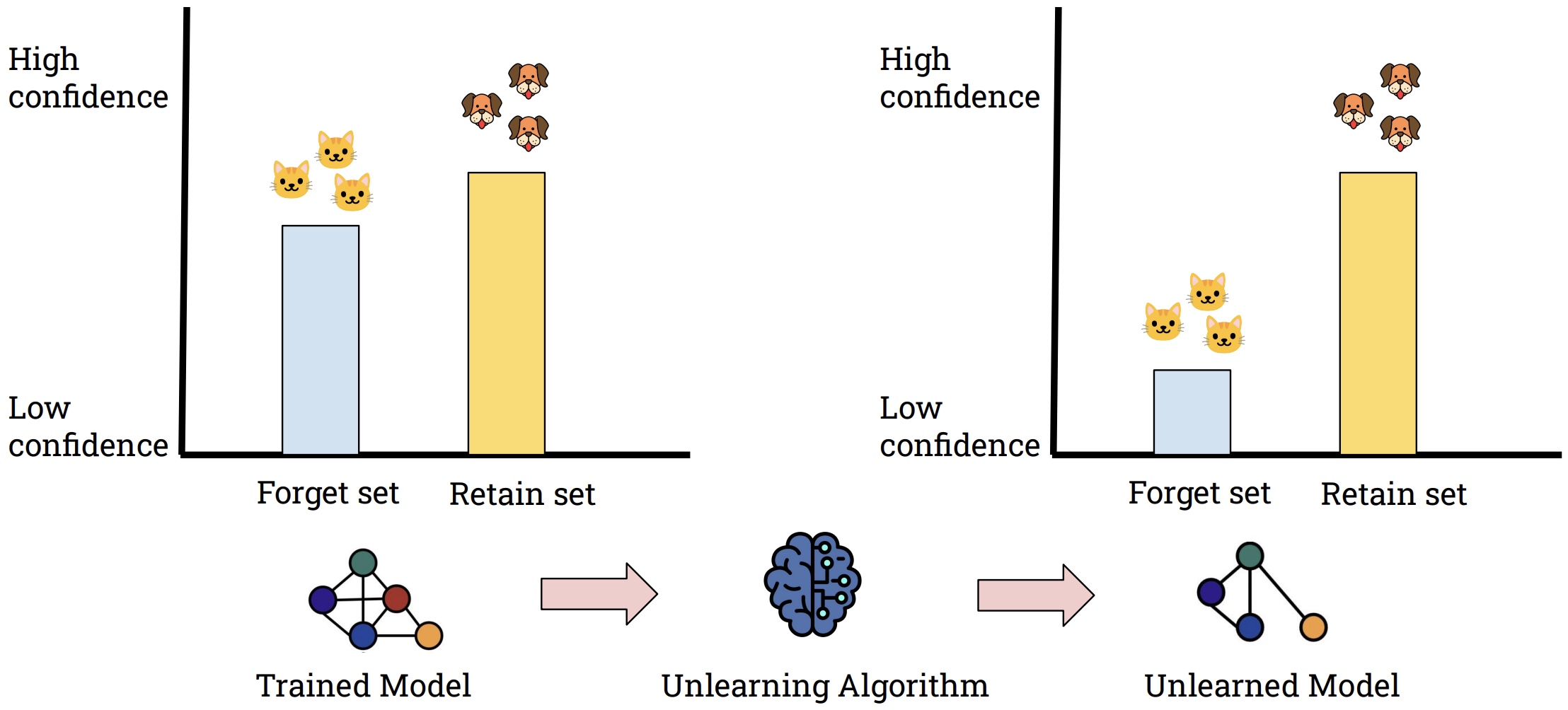
Machine learning systems are now deeply embedded in industries where privacy, compliance, and user trust matter — from financial services and healthcare to personalized digital experiences. As these systems learn from large volumes of sensitive data, the ability to unlearn becomes essential. Organizations may need to revoke the influence of outdated or harmful samples, while regulations increasingly mandate strict control over how data impacts model behavior. Giving models the ability to act as if they had never seen a particular datapoint — a process called “machine unlearning” — can address these concerns.
But machine unlearning is hard. Neural networks disperse information across millions of parameters, making it difficult to selectively remove the influence of one or more samples, collectively called the “forget samples”, without collateral damage. Traditional approaches often require expensive retraining or parameter updates that accumulate drift over time.
This is where Minimally Invasive Machine Unlearning (MIMU) comes in — a new framework that reframes unlearning as a model control problem. Instead of modifying model weights, MIMU temporarily disables a small, targeted subset of parameters responsible for predicting the forget samples. This leads to unlearning that is fast, reversible, stable, and minimally disruptive.
Why Unlearning Is Challenging
Typical unlearning methods fall into two categories:
1. Retraining the model (exact unlearning)
This ensures the forget samples leaves no trace, but:
- it is computationally expensive,
- slow,
- and impractical when unlearning must be done frequently.
2. Optimization-based unlearning
These approaches fine-tune the model to reduce its reliance on the forget data. But over time:
- the parameters can drift,
- generalization suffers,
- forget samples often lead to highly confident but incorrect predictions,
- and performance becomes unstable.
For real-world deployments, these limitations make existing unlearning approaches unreliable.
A Control-Based Perspective
MIMU takes a different approach. Instead of modifying the model’s parameters, MIMU asks:
Which specific parameters does the model depend on to predict the forget sample — and what if we simply turn those parameters off?
MIMU learns a binary masking policy that identifies exactly those weights. Forgetting is enforced through the prediction-alignment requirement:
\[ \big| P_{\theta}(y_i \mid x_i) – P_{\mathbf{m}_{\text{forget}} \odot \theta}(y_i \mid x_i) \big| \le \epsilon, \]with a strict sparsity constraint:
\[ \lVert \mathbf{m}_{\text{forget}} \rVert_0 = \delta. \]By masking only the parameters most responsible for the forget sample’s prediction, limited to a number \(\delta\) masked parameters, MIMU avoids modifying the model directly. This makes forgetting reversible, stable, and compatible with repeated unlearning operations.
How MIMU Works
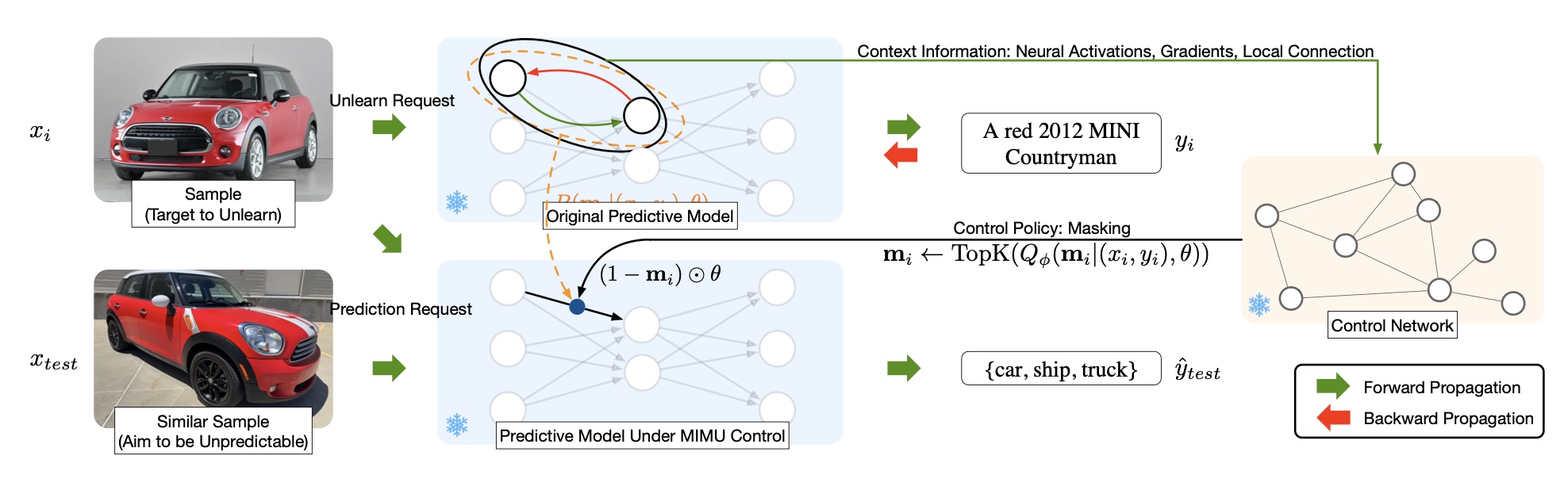
This figure shows how MIMU performs unlearning without altering the model’s parameters. A control unit (trained network) takes an unlearning request and outputs a mask over the model weights. During inference, the masked weights change the prediciton to be as if the model was never trained on the forget samples, while all other predictions remain nearly unchanged. This makes unlearning an inference-time operation with no retraining required.
Learning Which Parameters Matter
At the heart of MIMU is a conditional masking distribution — a learned function that outputs a distribution over possible masks for each sample. Instead of explaining this distribution symbolically in-line, we directly present it:
\[ Q_{\phi}(\mathbf{m}_i \mid (x_i, y_i), \theta). \]This distribution captures which parameters support the prediction of the sample.
To learn an effective masking distribution, MIMU minimizes a KL-divergence objective that encourages the learned distribution to match an ideal (but intractable) reference distribution. The ideal distribution should be able to replicate the model’s performance with minimal changes to the parameters.
\[ \arg\min_{\phi}\max_{\lambda} \left( – \mathbb{E}_{Q_{\phi}} \big[ \log P_{\mathbf{m}_i \odot \theta}(y_i \mid x_i) \big] + KL\big( Q_{\phi}(\mathbf{m}_i \mid (x_i,y_i),\theta) \,\|\, P(\mathbf{m}_i \mid \theta) \big) + \lambda \big( \lVert \mathbf{m}_i \rVert_0 – \delta \big) \right). \]The ideal distribution incorporates likelihood under masked parameters and a parameter-importance prior:
\[ P(\mathbf{m}_i \mid (x_i, y_i), \theta) = \frac{ P_{\mathbf{m}_i \odot \theta}(y_i \mid x_i)\; P(\mathbf{m}_i \mid \theta) }{ P_{\theta}(y_i \mid x_i). } \]MIMU brings these together in the main training objective:
\[ \arg\min_{\phi} \sum_{(x_i,y_i)} \left[ – E_{\mathbf{m}_i \sim Q_{\phi}} \big( \log P_{\mathbf{m}_i \odot \theta}(y_i \mid x_i) \big) – E_{\mathbf{m}_i \sim Q_{\phi}} \big( \log P(\mathbf{m}_i \mid \theta) \big) + E_{\mathbf{m}_i \sim Q_{\phi}} \big( \log Q_{\phi} \big) \right]. \]This objective encourages masks that:
- effectively disrupt predictions of forget samples,
- align with parameter importance,
- remain compact and minimally invasive.
A Parameter Graph That Captures Model Structure
One core challenge in machine unlearning is identifying which specific parameters contribute most to a model’s prediction for a given sample. Modern neural networks contain millions — even billions — of parameters, and not all of them play an equal role in a specific prediction.
To reason about parameter importance in a structured way, MIMU represents the model’s weights as a parameter graph. In this graph:
- Each weight is a node, representing a learnable parameter.
- Edges connect weights that interact through shared upstream or downstream neurons.
- Edges capture relational structure, allowing the controller to understand how parameters contribute jointly to predictions.
This parameter graph is visualized in the figure below.
(a) Weight Graph: parameters are connected if they share computational pathways.
(b) Node Representation: each parameter node includes local features such as its activation context and gradient signal.

These node features include the:
- incoming activation,
- outgoing activation,
- parameter value,
- gradient with respect to the sample’s loss.
This graph-based representation allows MIMU to focus its attention on the layers most directly responsible for producing predictions, rather than modeling the full network.
To operate on this parameter graph, MIMU uses a graph convolutional network (GCN) as its control unit. A GCN is well suited for this task because modern neural networks contain millions of parameters with rich relational structure — weights interact through shared upstream or downstream neurons, and their influence on predictions is highly interconnected. Instead of mapping the entire model and input sample directly to a mask, which would be infeasible at scale, the GCN efficiently aggregates local activation and gradient information from neighboring parameters, learns relational patterns through message passing, and identifies which weights most strongly support the prediction. This makes the masking process scalable, structured, and aligned with how neural networks naturally organize information.
How Hard Is a Sample to Forget?
Some samples depend on highly shared parameters, while others rely on more exclusive ones. MIMU quantifies this through an overlap score:
\[ c(\mathbf{m}_i) = \sum_{\substack{j \neq i}} \mathbf{m}_i^{\top} \mathbf{m}_j. \]- Low overlap → the sample’s prediction depends on unique parameters → easy to forget.
- High overlap → the sample is entangled with many others → harder to forget cleanly.
This gives practitioners a natural way to interpret the forgettability of different samples.
Unlearning Through Ranked Weight Masking
With the learned masking distributions, MIMU performs forgetting by applying a small ranked subset of the mask which:
- identifies parameters most uniquely supporting the forget sample,
- ranks them by exclusivity,
- apples a binary mask to remove those parameters,
- reduces the model’s confidence on the forget set below a threshold,
- and preserves original model’s accuracy on the remaining and unseen data.
Because the underlying model weights remain intact, this process is:
- reversible,
- predictable,
- robust across repeated unlearning,
- and is computationally efficient.
Experimental Highlights
Across MNIST, Fashion-MNIST, CIFAR-10, and synthetic datasets, MIMU demonstrates:
- effective forgetting,
- minimal impact on retained data,
- stable behaviour across many unlearning rounds,
- uncertainty-driven forgetting rather than incorrect confident predictions,
- significant speedups — forgetting becomes an inference-time operation.
These properties make MIMU a strong candidate for real-world unlearning in production environments.
Why MIMU Matters
MIMU isn’t simply a new unlearning method. It represents a shift toward controlled, reversible model behaviour.
It offers:
- fast, production-ready unlearning,
- no parameter drift over repeated requests,
- interpretable masks,
- compatibility with modern architectures,
- reversible, non-destructive changes.
As AI systems grow more responsible and regulated, the ability to forget safely, efficiently, and repeatedly will become foundational. MIMU offers a practical and principled path forward.
Conclusion
Minimally Invasive Machine Unlearning reframes forgetting as a control problem. By learning how to selectively disable the parameters responsible for specific predictions — while keeping the rest of the model intact — MIMU enables forgetting that is efficient, stable, interpretable, and suitable for real-world use.
As data governance and safety expectations evolve, techniques like MIMU will be essential in building machine learning systems that remain trustworthy and aligned with user expectations.