The problems with large language models are well documented. You’ve seen the headlines: hallucinations, confident errors, and responses you can’t trust.
- An airline was required to compensate a passenger after a chatbot provided incorrect information about its refund policy citing rules that didn’t exist.
- A lawyer was caught citing non-existent case law in a legal brief drafted with an AI tool.
- Doctors using transcription tools have seen notes “invent” quotes that patients never actually said.
In high-stakes domains like medicine and law, those failures aren’t just inconvenient. They can carry real consequences for professionals, for organizations, and for the people they serve.
What makes the promise of these tools so compelling is how much efficiency they can unlock by taking on time-consuming, mind-taxing work. Summarization is a perfect example. Why read a 50-page report when a tool can extract the key points in 500 words?
In theory, it’s a win: less cognitive load, more time for higher-level work, and maybe even some relief from burnout. But in practice, the unreliability of AI-generated summaries often forces professionals to verify what the tool produced, replacing one task (summarizing) with another (fact-checking).
A 2025 BBC analysis of AI assistants answering questions about the news found accuracy problems were common.1 More than half (51%) of the responses were judged to have significant issues. Even when the tools cited BBC reporting, 19% still introduced factual mistakes including wrong statements, numbers, or dates. And when the answers included quotes, 13% of those quotations were either altered from the original or weren’t present in the cited article at all. This is problematic because it misinforms the reader, erodes trust in the brand, and can expose the publication to legal action from people quoted or interviewed.
In a 2025 article in Interactive Journal of Medical Research the authors caution clinicians that LLM hallucinations aren’t just a nuisance, they can actively distort clinical reasoning.2 A model may “fill in” details that were never provided, wrongly linking symptoms, lab findings, or imaging features to a disease and nudging a clinician toward the wrong diagnosis or treatment plan. It may also misstate how accurate a test or procedure is, encouraging overconfidence in a weak diagnostic tool. And because these systems learn from incomplete and sometimes outdated medical sources, they can propose workups, therapies, or plans of care that are inappropriate, out of date, or mismatched to the patient’s full context, especially when key patient details are missing or never requested.
A paper published in Royal Society Open Science in late April 2025 found that popular chatbots can subtly “inflate” the meaning of scientific results.3 In tests comparing AI-written summaries with expert-written ones, systems including ChatGPT, Llama, and DeepSeek were far more prone to smoothing out nuance and stretching conclusions beyond what the original studies supported. The researchers also observed a troubling pattern across model generations: newer versions tended to drift further toward broad, overconfident takeaways than earlier releases. Their takeaway wasn’t to abandon these tools, but to treat them like high-risk assistants adding checks in the workflow that flag overreach, missing caveats, and other signs of oversimplification before the summary is used to inform decisions.
One of the driving reasons these errors show up in AI summarization is baked into how large language models actually generate text. An LLM doesn’t “read” a document the way a person does, and it doesn’t retrieve facts from a verified database. It breaks your input into tokens (chunks of text—sometimes a word, sometimes part of a word), and then uses patterns learned from massive training data to predict the most likely next token, over and over, until it has produced a complete response. Each step is essentially a probabilistic guess: given everything in the prompt so far, what token is most likely to come next? That approach is great for producing fluent language, but it also means the model is optimized for plausibility, not truth. When the source text is complex, ambiguous or missing key context, the model can “smooth” uncertainty into confident-sounding details, compress nuance, or invent connective tissue that wasn’t there.
Reliable LLM Summarization
Types of summarization
First, it’s important to understand the distinction between two approaches to summarization: abstractive and extractive.
Abstractive summarization is the one most people recognize. It paraphrases and synthesizes information from the source text to generate new sentences. Extractive summarization, by contrast, pulls phrases or sentences directly from the original document and presents them verbatim. The goal is to remove as much text as possible while still preserving the most important information and, crucially, its meaning and context.
Abstractive summarization is still the default in many mainstream LLM tools, largely because it produces smooth, readable prose. But in high-stakes domains like medicine, extractive methods can be a better fit precisely because they stay closer to the source and reduce the risk of “creative” interpretation.
Which raises the real question: how do we make summarization safer without losing the efficiency we want from it? Put another way: how do we get LLMs to reliably identify the most important factual content in a document and extract it cleanly so the reader can trust what they’re reading while taking in far less?
Our solution
We set out to tackle this problem by introducing Conformal Importance Summarization. At a high level, it’s a new way to make summarization more disciplined, especially when accuracy and context matter.
This is the first time that conformal prediction has been applied to LLMs for summarization. Conformal prediction is a statistical framework that’s increasingly used to quantify uncertainty in the outputs of prediction algorithms. Instead of forcing a single “best guess,” it converts predictions into prediction sets: groups of candidates that come with strong, finite-sample coverage guarantees (in plain terms: reliability properties that hold even when you don’t have infinite data).
Learn the essentials of conformal prediction in this blog
Applied to summarization, that shift matters. It creates a principled way to identify which pieces of information the model can select with confidence so the summary is less likely to drift into overgeneralization or outright fabrication.
The promise here is simple: more reliable summaries that preserve facts and context while still extracting the key information a reader actually needs and doing it with stronger guarantees than what the current generation of LLM summarizers can offer.
Conformal Importance Summarization first takes an input document \(x\) and breaks it into a set of sentences \(\{c\}\). Each sentence \(c\) is shown to an LLM which scores how important it is in the context of the document, called \(R(c; x)\). We then define a filtration function which removes all sentences with importance less than a threshold \(q\):
\begin{equation}
F_q(x) = \{c\in x \mid R(c;x) \geq q\}.
\tag{1}
\end{equation}
The threshold is carefully calibrated using the principles of conformal prediction, based on a calibration dataset of documents where the important sentences \(y^*\) are labeled. This guarantees with high confidence \(1-\alpha\) that, on a new document, the filtration does not remove important sentences:
\begin{equation}
\mathbb{P}[y^*\subseteq F_q(x)]\geq 1-\alpha.
\tag{2}
\end{equation}
An example document is shown in the image below. Sentences in blue are considered ground-truth important (\(y^*\)), while red text with strikethroughs were filtered out by our method. In this case, Conformal Importance Summarization retained all important information and filtered out 66% of the unnecessary sentences.

For the same document, the image below shows the individual importance scores \(R(c; x)\) for each sentence in order, as well as the conformal threshold \(q\) as the dashed red line. Sentences with low scores, shown in red, were filtered out.

Testing the method
To test whether conformal prediction could make extractive summaries more reliable, we ran a series of experiments built around the practical question: can we attach statistical guarantees to how well a summary retains the sentences that matter most?
We evaluated the approach across five datasets spanning very different domains, including:
- scientific papers, with summaries written by authors and peer reviewers
- corporate earnings calls and their corresponding summaries
- doctor–patient conversations paired with clinical-style summaries
- Chinese-language customer service calls and summary outputs
- news articles from CNN and the Daily Mail, aligned to human-written summary sentences
We then tested the method using five LLMs: GPT-4o mini, Llama3-8B, Qwen3-8B, Gemini 2.0 Flash-Lite, and Gemini 2.5 Flash.
First an initial “sanity check” confirmed that our setup behaved the way the theory predicts, satisfying the coverage guarantee in Equation (1). We then ran the full suite of experiments for Conformal Importance Summarization.
How we evaluated quality
We used a set of complementary metrics to capture what matters in real summaries.
First, we used importance scoring to evaluate ranking quality: how consistently each method separates high-value sentences from those that can safely be dropped. We then used area under the precision–recall curve (AUPRC) to capture the trade-off between conciseness (precision) and completeness (recall).
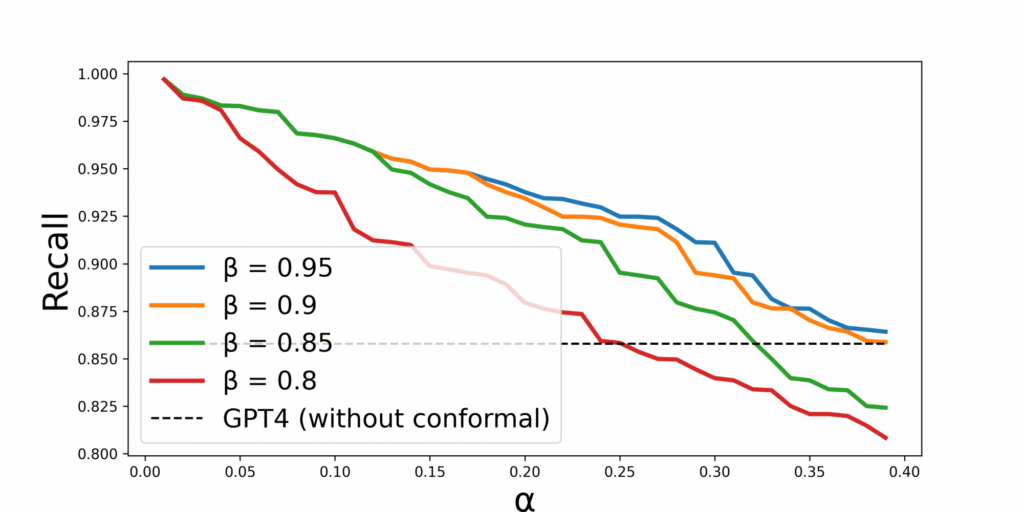
Next, we measured how effectively the method compresses information while preserving what’s essential. We set targets for error tolerance (\(\alpha\)) and target recall (\(\beta\)), tracked the proportion of sentences removed, and measured the empirical recall achieved by the resulting summaries.
See full experimental details in the paper, published at NeurIPS 2025
What we found
Across the tests, one result stood out: we could dial the behavior of the summary up or down in a controlled way. By adjusting \(\alpha\) (how much risk/error we’re willing to tolerate) and \(\beta\) (the recall threshold we’re targeting), we could tune the balance between how strict the summary is about retaining important content and how aggressively it shortens the source.
In plain terms: increase \(\alpha\), and empirical recall tends to drop. Lower \(\beta\), and you see the same effect. This is the predictable trade-off you want when you’re deciding how much information you can afford to lose before a summary becomes unreliable.
This points to something important: instead of relying on whatever a model happens to produce, our method gives you levers to control the output.
And recall wasn’t the only goal. We also tested conciseness: how far can you compress a document before the summary starts shedding critical content? The pattern was consistent: higher \(\beta\) produces longer, more conservative summaries, while lower \(\beta\) produces shorter summaries that may miss more important information. And for a given \(\beta\), higher \(\alpha\) generally enables more compression. The value is that you can choose where you want to land on that spectrum, depending on the stakes of the task.

What we learned
Our experiments led to a few clear conclusions.
First, we showed that Conformal Importance Summarization can produce flexible, reliability-oriented extractive summaries and, importantly, it gives you practical control over the trade-off between completeness (recall/coverage of important sentences) and conciseness (how aggressively the text is shortened).
That means an end user can tune the summary to match the moment: more compressed when they need speed, more conservative when the cost of missing key information is high. A legal expert, for example, might start with a short extractive “gist” of a legal brief, then increase the retention settings to produce a longer, more detailed version for a closer read.
Second, the experiments validated the core promise of the conformal approach: by adjusting \(\alpha\) (error tolerance) and \(\beta\) (target recall threshold), we can predictably shift where a summary lands on the conciseness–completeness spectrum. In other words, the system gives you levers, not just a single opaque output.
Third, our tests also suggest that modern LLMs can be strong sentence-importance judges. In some cases, an LLM used directly as an extractive summarizer can produce very short summaries. The trade-off is that it provides no statistical guarantee on coverage and no reliable user control over how much important information is retained. Conformal Importance Summarization, by contrast, is designed to give much finer control over the desired outcome, especially when you want higher confidence that key content wasn’t silently dropped.
Further out on the horizon, the framework could be extended to more general types of labels. A more ambitious direction would be to explore how these ideas might translate to abstractive summarization, not just extractive selection.
If LLM summarization is going to become a routine part of knowledge work, we can’t treat its failures as edge cases or ask professionals to “just double-check it.” In high-stakes settings, reliability has to be designed into the workflow. Conformal Importance Summarization points to a practical path forward: keep summaries grounded in the source text, make the trade-offs explicit, and give users real control over how much risk they’re willing to accept when they compress information.
References
- Archer, P. Representation of BBC News content in AI Assistants. BBC, 2025 bbc.co.uk/aboutthebbc/documents/bbc-research-into-ai-assistants.pdf ↩︎
- Roustan, D. and Bastardot, F. The Clinicians’ Guide to Large Language Models: A General Perspective With a Focus on Hallucinations. Interactive Journal of Medical Research, 2025. ↩︎
- Peters, U. and Chin-Yee, B. Generalization bias in large language model summarization of scientific research. Royal Society Open Science, 2025. ↩︎


