
OpenAI launched GPT 3.5 in November 2022, responding with human-like text and inspiring people to dream up new applications for AI. In the world of traditional ML – regression, classification, etc. – assessing which applications to invest in tends to be difficult; in the world of generative AI, with its profound potential impact on corporate productivity, even more so. In TD, as in any bank, realizing impact requires contextualizing the idea within a complex risk and regulatory environment. In this blog post, we discuss how we delivered a Retrieval-Augmented Generation (RAG) solution for our customer support agents from a product, delivery, and stakeholder management point of view.
The problem we were trying to solve was that employees found it difficult to find and navigate through required documents to answer customer queries using traditional Knowledge Management Systems (KMS) such as intranet sites or rules-based chatbots. Our idea was to revolutionize TD’s KMS through an application of RAG to provide a better customer experience. We were motivated by the potential application throughout the organization, which includes a myriad of business units plus functional complexity, and scale with over 95,000 colleagues. Our approach was to start in one representative segment with passionate business support: TD’s North American Customer Operations (NACO) Canadian contact center with the idea that we’d prove it out, learn lessons and scale rapidly.
Within the bank, building a cross-functional AI model requires colleagues from many diverse teams. Required roles include technical AI experts and Product Owners, which Layer 6 has, but also an AI platform team, data stewards, front and back-end developers, business leaders, and business Subject Matter Experts (SME). In our RAG context, the data was NACO policies and procedures, and the SMEs were people intimately familiar with those documents, how agents used them, and crucially – what the correct answers should be to questions about them. NACO recruited two star 2nd level support agents to join the AI development team.
RAG Development
Developing a RAG model needs Generative AI infrastructure, a document corpus, representative queries for testing, and the inference pipeline components such as a document retriever and response generator.
Infrastructure
Building a secure environment with access to Generative AI tools required overcoming challenges related to service availability, scalability, and compute power. We collaborated with our Platform team and Risk partners who spun up new environments, integrated them with newly certified essential services and built the end-user application and ancillary services required such as logging databases required for training, risk, and compliance purposes. Over the course of development, many new models were released, which required rapid infrastructure deployment and frequent collaboration between teams that strengthened relationships across the bank. Additionally, our Platform colleagues addressed the substantial computational and storage demands of AI models, especially large language models (LLMs), by leveraging scalable cloud solutions such as Azure OpenAI to get to market quickly. These efforts enabled our team to rapidly prototype, optimize, and deploy our RAG model.
Read more about how we deploy models safely
Document Corpus
Our traditional KMS contained the corpus, but we had to convert the documents into a RAG-friendly format. To enable this, our Platform team developed a document ingestion framework with a plug-and-play architecture to scale and support different types of documents and to be reused for future use cases. The documents for our initial release were dynamic web pages so we converted the content into static markdown files. Preserving content meaning during this conversion was critical. One of the ways we maintained meaning was by using markdown headings and ensuring that the dynamic content
aligned with the appropriate headings. These headings proved to be effective delimiters when chunking documents and creating embeddings for our retriever.
Queries
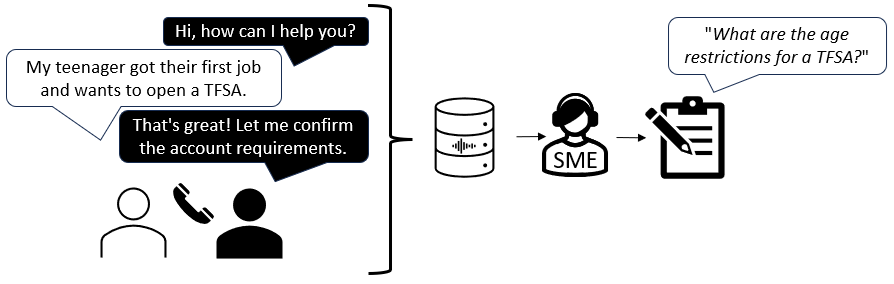
Getting representative queries for development was a challenge because the model was not yet built, and it was uncertain how users would interact with this new technology. Our data SMEs were crucial for coming up with queries for testing and development. The initial idea was to listen to call center recordings and extract the verbal questions into written queries. However, it was immediately clear from the recordings that the conversational communication during a call was not representative of how users would interact with a chatbot. The data SMEs used their experience to distill the conversations into
queries that could be used for model development (Figure 1).
Retrieval
We started with a publicly available RAG pipeline1 and found our performance was limited by poor retrieval. Often, the wrong documents were retrieved for a given query. We worked with the SMEs to define a test set of queries, which contained the ground-truth set of documents for each query. This way, our scientists could rapidly iterate and apply their efforts towards improving retrieval.
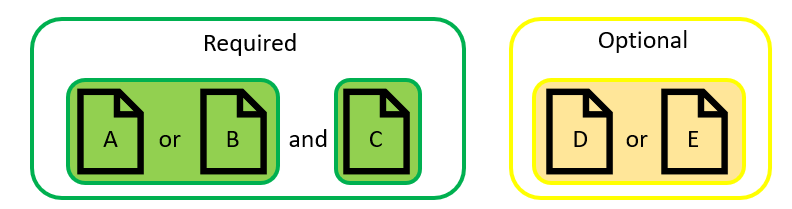
Defining required documents seemed straightforward initially, but there were many nuances to this based on SME experience. For example, when answering a question, should the response be brief and only include strictly required information or should the response be more comprehensive, and include potentially relevant information for additional context? Or what if multiple documents contain the answer – are certain documents preferred over others? Answering these questions required consultation with our SMEs and business stakeholders. We learned the responses should be brief because call handle time was important, additional context after the core response was considered as a bonus, and document preferences could be considered through qualitative feedback. We developed annotation forms that our SMEs used to define different sets of documents for each query (Figure 2), enabling rapid optimization of the retrieval component.
Generation
When building the generation component, we learned that rapid model improvement required frequent and in-depth SME and AI team engagement. We generated model responses, which our SMEs analyzed with a fine-toothed comb and evaluated using a custom rubric. After the first evaluation, we realized the rubric was sometimes difficult to apply and we had to iterate through multiple versions to define precisely what made a “good” response. The final rubric went beyond common RAG metrics such as faithfulness to address the holistic requirements of the business, and considered response quality, completeness, relevancy, length, hallucinations, and ability to abstain when appropriate.
Once the rubric was finalized, we had our first set of reliable KPIs to increase. The main KPI was a binary pass/fail evaluation of the response, which had to be complete, concise, and contain no errors or extraneous information – essentially a perfect “textbook” response that a human expert would provide. The initial performance on a batch of a few hundred queries was very low.
Customization
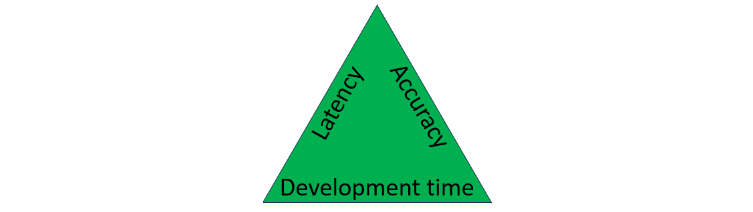
It was clear that improving the model would require adding deep, business-specific context. We considered fine-tuning models but at the time, there was too much uncertainty about the required development efforts, infrastructure requirements, and potential downstream improvements, especially since the corpus documents can be updated daily. Instead, we worked closely with our SMEs to categorize the model failures into themes that we could address with model experiments. There was no shortage of experiment ideas, but we had to carefully prioritize which ones to run and ultimately implement in the model based on their impact to response quality, latency, and development time (Figure 3).
One of the model improvements we implemented was a reranker step which was designed to better order the document chunks from the retriever. We started by integrating a third-party reranker into our secure development environment. The reranker had low latency and was fast to implement, but we found it had poor accuracy because it was not trained on TD data. After several iterations we developed our own GPT-based reranker seeded with TD data to increase accuracy. The reranker included a pre-processing step where it would filter out chunks whose search scores did not exceed a calibrated threshold. The thresholding strategy was implemented using conformal prediction to select the optimal number of chunks in real time.
Read more about conformal prediction here
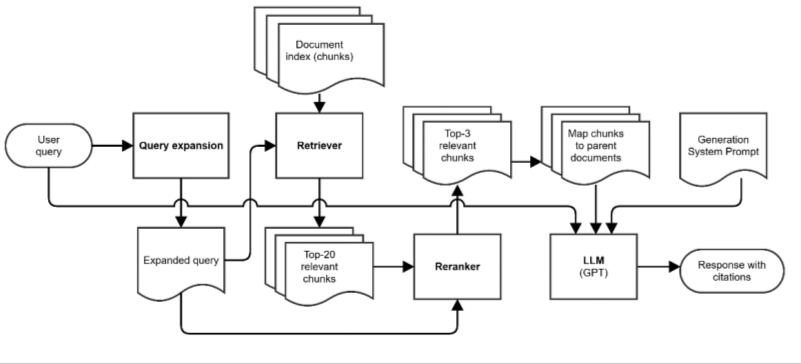
Other model improvements included handling business-specific acronyms and shorthand, adding a query expansion step to improve retrieval, optimizing model choices for different components, tuning document chunking strategies, improving the context sent to the LLM generation node, and optimizing LLM prompts throughout the RAG pipeline (Figure 4).
Conclusion
The collaboration between scientists and SMEs often involved joint prompt engineering sessions with real-time evaluation and feedback from SMEs. The fusion of expertise from both domains was critical to success, which is true for any ML model, but acutely so in RAG when AI scientists alone cannot reliably assess model response quality.


