
At Layer 6, we develop models that are having a significant impact on the lives of our customers. Ensuring that our models work as intended in production is of the utmost importance, so our machine learning (ML) pipeline deployment process is extremely thorough.
Typically, whether it’s a simple logistic regression model or a complex large language model (LLM) workflow, models are trained and evaluated offline. Once the models have sufficient offline performance, they’re deployed online to be used with live customer data.
In many cases, hosting the final model pipeline in production to run with live data is the be-all and end-all. Best practices today to ensure production quality of ML pipelines focus on monitoring model performance and service health. At Layer 6, however, the sensitive nature of our models requires that we have additional guardrails in place to make sure that our pipelines are working safely, and predictably, while also maintaining performance.
In this blog post, we focus on a key part of our deployment process: regression testing. We take inspiration from the tried-and-true standards of decades of deploying software and apply it to the bourgeoning world of ML pipeline deployment.
ML Pipelines are Software
Software typically has tests that must pass as a part of its deployment process. Unit tests are numerous, with each test evaluating a small piece of the code. If every test passes, then you know that each individual piece is working as intended. Alongside unit tests, you have integration tests, which test if the unit tested pieces work well together, and functional tests, which test the functionality of the software.1 During deployment, if these tests are used to measure the performance of the newer version of software against older versions of software, they are called regression tests.
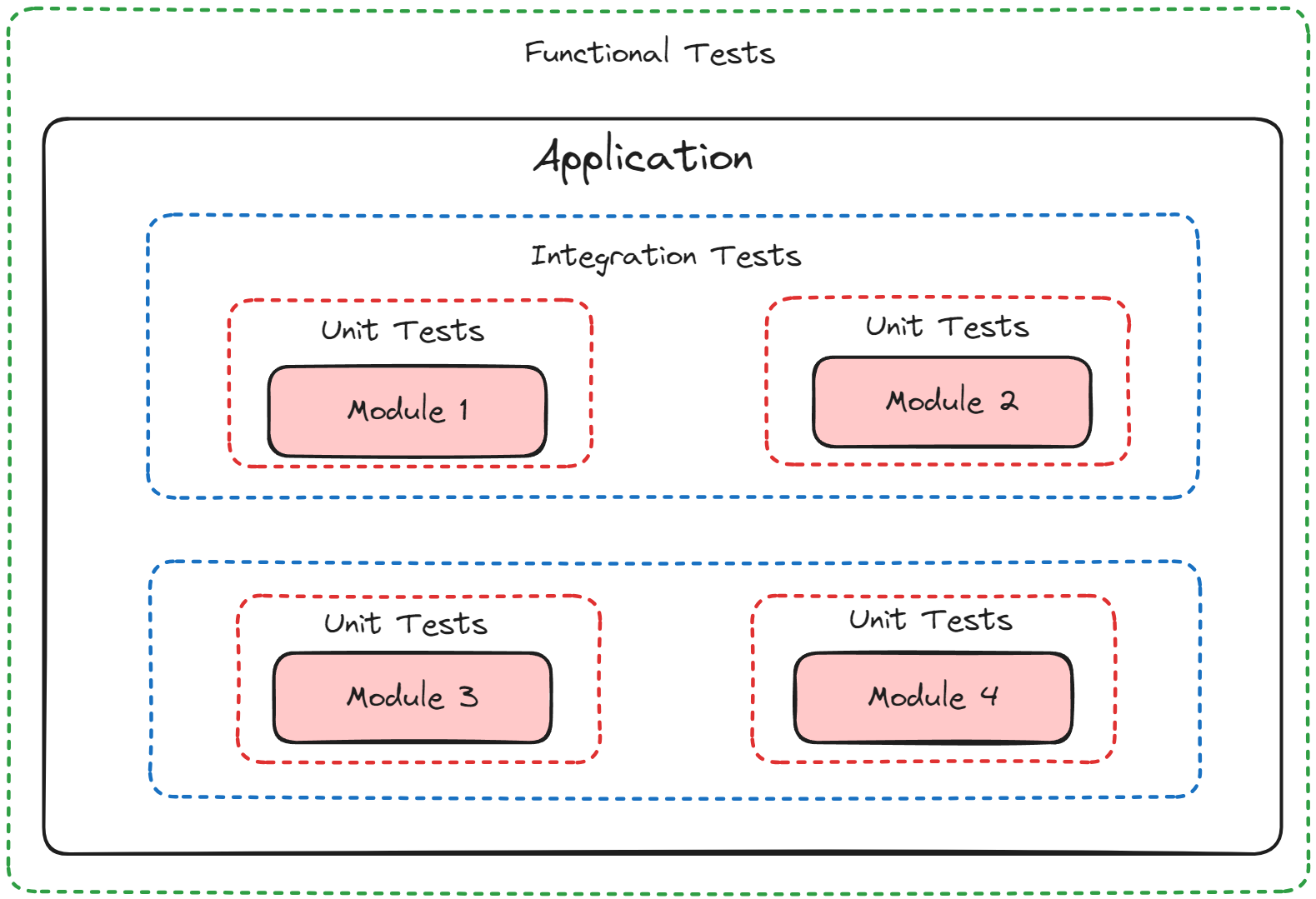
Software tests are easier to design because software (for the most part!) is well defined. Software is explainable, which makes it conceptually easier to test, unlike ML pipelines. ML pipeline behaviour is likely well-defined but cannot be guaranteed based on the types of models, since models work on unseen data. The fuzziness around model behaviour can make it difficult to provide exact guarantees. When building models for the Bank, this is a major concern and efforts need to be made to mitigate it.
For the most part, models don’t really change until they are refreshed or decommissioned, so sufficient pipeline testing during the initial deployment should be enough, right? Unfortunately not, as redeploying the pipeline is inevitable.
The Inevitability of Deployment
It would be ideal to freeze the pipeline in production, with no plans of ever changing it. The initial state of the pipeline during launch is the exact same model that remains throughout its lifecycle, and so we have some mitigation for unexpected behaviour. In reality, even if you make no code changes to the pipeline, you may still have to do deployments. For example, some of your dependencies might be deprecated, or there may be urgent security patches that you need to apply. This will require a re-deployment with changed versions of dependencies.
For example, a minor version upgrade in SciPy caused the Apache Recommenders project to break2. Fortunately, their tests caught the runtime error, and it did not propagate to their users. However, logical errors are more insidious, and can sneak into production pipelines through dependency upgrades. In an ML pipeline, seemingly minor logical errors can propagate, leading to unintended model behaviour. Therefore, we need a robust way to test our ML pipeline as a part of every deployment.
Regression Testing ML Pipelines
The ML pipelines built at Layer 6 can depend on many internal and open-source libraries, which can cause large dependency trees, and the produced pipelines can have a shelf-life of many years. This combination can increase the likelihood of a deployment needed during the pipeline’s lifecycle.
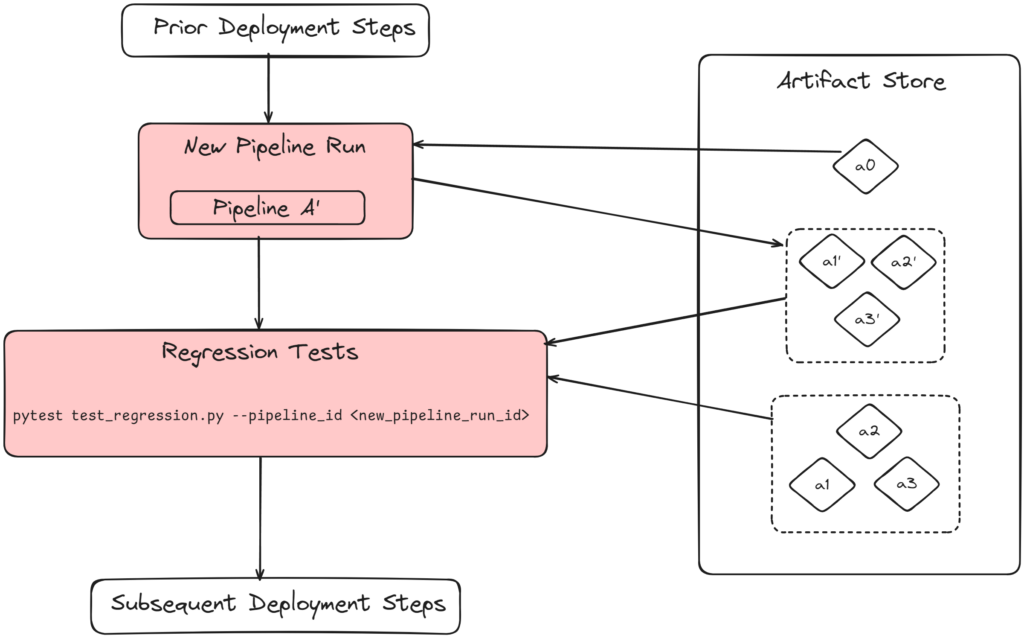
As a part of our internal ML framework, we provide a way for users to write regression tests for their pipelines. When the ML pipeline is ready for its initial launch, we take stock of the artifacts needed by the pipeline as well as the artifacts produced. Artifacts needed by the pipeline could include sample data, configurations, model weights, or anything else that is needed to run the pipeline. Artifacts produced by the pipeline could include inference results, performance metrics, as well as any other information that is consumed by downstream users of the pipeline. These artifacts are saved as reference artifacts.
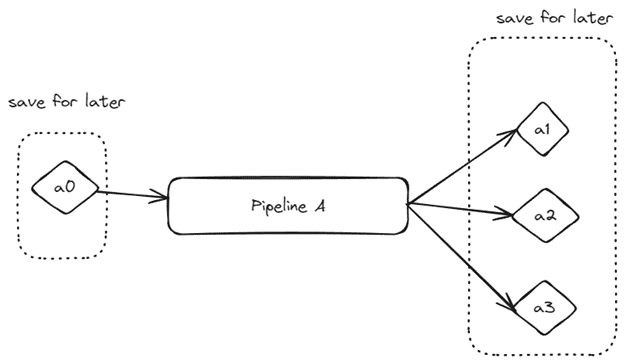
During deployment, our framework runs the pipeline with the previously stored reference artifacts and generates a new set of artifacts. Users write custom regression tests that compare the newly generated artifacts against the initial reference artifacts.
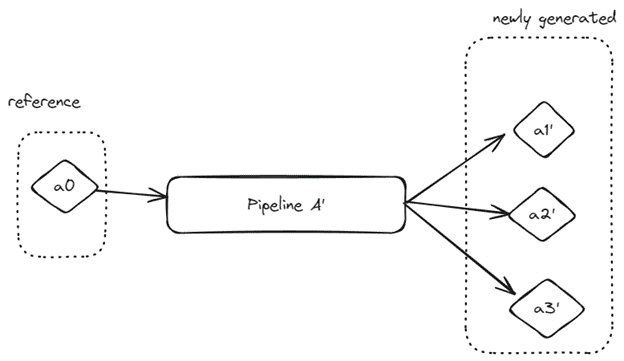
With our internal framework, users can define their comparators for the reference and generated artifacts. For example, XGBoost models can be compared using their booster JSON files. A common test our users write compares the evaluated results dataframe from the reference artifacts against the newly generated one. Care is taken to ensure that floating points are within the expected tolerance.
# in framework code
class PandasDataArtifact:
def __init__(self, data):
self.data = data
def get_data(self):
return self.data
class ArtifactLoader:
def __init__(self):
self.loader_client = LoaderClient() # external dependency
def load(self, pipeline_id, artifact_id):
return self.loader_client.load(pipeline_id, artifact_id)
# conftest.py
import pytest
def pytest_addoption(parser):
parser.addoption("--pipeline_id", action="store", default="")
@pytest.fixture
def pipeline_id(request):
return request.config.getoption("pipeline_id")
@pytest.fixture
def reference_pipeline_id():
return "123" # defined as a part of user code
@pytest.fixture
def artifact_loader():
return ArtifactLoader()
# test_regression.py
import pytest
import pandas.testing as pdt
def test_regression_evaluated_results_from_model(artifact_loader, pipeline_id, reference_pipeline_id):
reference_results = artifact_loader.load(reference_pipeline_id, "evaluation_results").get_data()
generated_artifact = artifact_loader.load(pipeline_id, "evaluation_results").get_data()
These regression tests will run as a part of the deployment pipeline, and act as barriers to deployment upon failure.
Conclusion
ML pipelines in production will eventually require updated deployments. Even if the pipeline code does not change, the underlying dependency upgrades may cause differing behaviour, which can propagate to your model’s performance. Developing regression tests helps mitigate the likelihood of this happening and provides a safer methodology for pipeline deployment, especially for sensitive industry and applications.

