This blog post is about our paper which was published as a Highlight paper at CVPR 2024. Please refer to the full paper for complete details. Our code is also publicly available here.
We live in a multimodal world. As humans, we simultaneously interact with data sources spanning many modalities including text, image, video, and audio data. We would therefore expect our AI systems to behave accordingly, meaning that they should be able to jointly reason across our modalities of interest. This is the overarching goal of multimodal machine learning, to build universal models that can jointly perceive data of various modalities. However, a major challenge in building such systems stems from the heterogeneity of modalities. For example, an image is continuous while text is discrete, so building a single model for both of them is intrinsically non-trivial. Now, if we could instead map these modalities into a more homogeneous space first, it should make our lives easier. We call this task multimodal alignment, or alternatively multimodal fusion, where the goal is to learn a single unified latent space that is shared between multimodal inputs.
Current Approaches are Inefficient
Recent successes in multimodal fusion (e.g., CLIP1 and ALIGN2) have been largely driven by large-scale training regimes. On the one hand, it is common to jointly train separate encoders for each modality end-to-end and from scratch which requires substantial GPU resources. On the other hand, massive datasets of paired multimodal inputs are usually required, which are expensive to collect and annotate at scale. Finally, jointly training modality-specific encoders means that they become tightly coupled; modifying any aspect of either network would generally require completely re-training both networks end-to-end. This presents a critical bottleneck in practice, as multimodal models cannot keep pace with research advancements in each underlying modality without performing expensive re-training.
Altogether, these challenges present a cost that is unacceptable for many practical scenarios where access to compute is limited and where multimodal data is scarce. The main goal of our work is therefore to design an efficient framework that can democratize research in multimodal fusion and thus equalize access to advanced multimodal capabilities.
Introducing FuseMix
Towards Efficient Multimodal Fusion
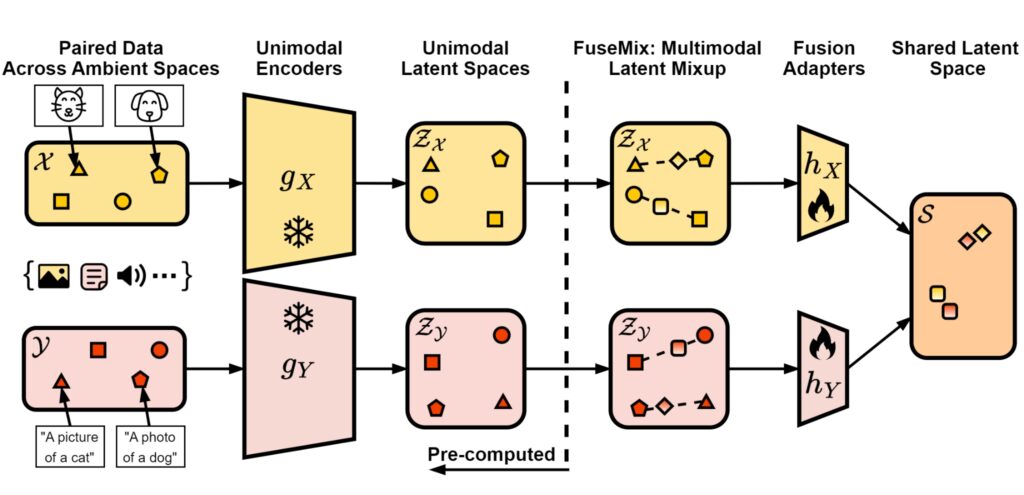
Our first key insight is that off-the-shelf unimodal encoders that have been pre-trained on large amounts of unimodal data already encode rich semantics that should provide an effective bootstrap for multimodal fusion. This means that to perform multimodal fusion, we can simply train lightweight heads, which we call fusion adapters, on top of frozen unimodal encoders. This design offers important advantages.
Computational Improvements
Since we are keeping the unimodal encoders frozen, they are not needed for backpropagation. We can thus simply pre-compute samples from their latent space and then discard the underlying unimodal encoders while training. This step ensures that we do not need to store large encoders in memory during multimodal fusion, which significantly reduces computational requirements. The only parameters stored in memory during fusion are those of the learnable fusion adapters which are extremely lightweight compared to the unimodal encoders. In fact, in all of our experiments, we only require a single GPU at every step, a far cry from most recent state-of-the-art methods!
Paired Data Efficiency
Bootstrapping from pre-trained unimodal encoders means that we can directly benefit from the rich modality-specific semantics that they already encode. Learning this information from scratch might be redundant for multimodal fusion, so leveraging pre-trained unimodal encoders can be an effective bootstrap to reduce the need for large-scale multimodal paired data.
Plug-and-Play Framework
Our modular approach to multimodal fusion is agnostic to both the choice of unimodal encoders and to the underlying modalities. This means that by combining arbitrary pre-trained unimodal encoders, we can decouple unimodal learning from multimodal fusion. Therefore, as the development of unimodal encoders continues to advance, we can easily and efficiently leverage new unimodal encoders for multimodal fusion in a plug-and-play manner.
FuseMix: Multimodal Latent Mixup
Given our aim of performing multimodal fusion with minimal samples of paired data, it would seem intuitive to also leverage data augmentations to generate synthetic multimodal pairs. As such, we introduce a simple yet effective multimodal augmentation scheme on latent space that is agnostic to both the involved modalities and to the choice of unimodal encoders. Our approach, which we call FuseMix, is inspired by mixup3. We generate augmented samples by taking random convex combinations of samples in the latent space of each unimodal encoder. By sharing the mixing coefficient across modalities, we can ensure that augmented samples remain semantically meaningful multimodal pairs. The simplicity of our FuseMix fusion algorithm is illustrated below, requiring only a few lines of code.

How Does FuseMix Perform in Practice?
Cross-Modal Retrieval
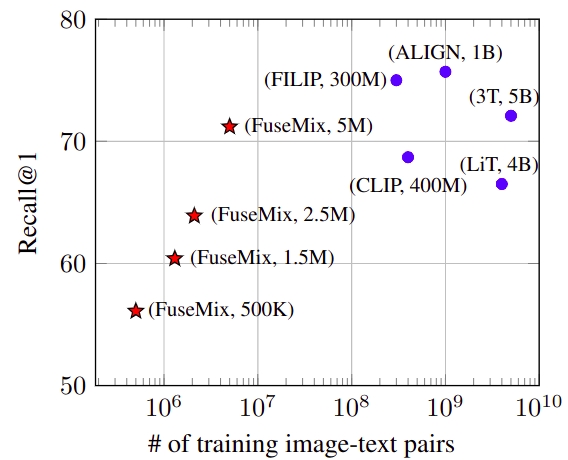
Now that we’ve taken a bit of a deeper dive into our methodology, let’s see how things hold up in practice. Our main task of interest is retrieval, especially cross-modal retrieval. While we provide a more comprehensive evaluation of both image-text and audio-text retrieval in the full paper, our main result can be summarized in the following figure (note the x-axis is in log-scale). We are able to obtain highly competitive fused multimodal models, which in certain cases even outperform state-of-the-art methods in cross-modal retrieval, all while using orders of magnitude less compute and data. For example, we use ∼600× less compute (∼5 vs. ∼3000 GPU days) and ∼80× less image-text pairs (∼5M vs. ∼400M) than CLIP to perform multimodal fusion, yet are still able to outperform it in recall for the text-to-image retrieval task on the Flickr30K test set4.
Audio-to-Image Generation
We also explore how our framework can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Many text-to-image diffusion models receive their conditioning input via an auxiliary text model which encodes the text input into its latent space. If we can somehow take an arbitrary audio encoder and align it to the latent space of this auxiliary text encoder, we should in theory be able to replace the text prompt with an audio prompt to generate images conditioned on audio instead of text. It turns out that our method can be easily extended for this purpose, and the result is a diffusion model that can generate reasonable images given audio prompts (we also show samples with corresponding text prompts as a reference). Cool, right!?

Some Concluding Thoughts
While our full paper contains more comprehensive results and some additional analysis on quantifying the importance of dataset quality and diversity in settings with access to limited multimodal pairs, it should now be evident that bootstrapping from arbitrary pre-trained unimodal encoders and performing multimodal augmentations on latent space can dramatically improve both compute efficiency and data efficiency for multimodal fusion. It is worth highlighting that since our framework essentially considers unimodal encoders as black box models (i.e., we only use the latent encodings from their penultimate layer), this opens up exciting applications whereby we can also perform multimodal fusion with closed-source encoders only accessible via an API.
If you find our work relevant to your research, please consider citing the following paper:
@inproceedings{vouitsis2024dataefficient,
title={Data-Efficient Multimodal Fusion on a Single GPU},
author={No{\"e}l Vouitsis and Zhaoyan Liu and Satya Krishna Gorti and Valentin Villecroze and Jesse C. Cresswell and Guangwei Yu and Gabriel Loaiza-Ganem and Maksims Volkovs},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024},
}References
- Radford, et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PMLR, 2021. ↩︎
- Jia, et al. Scaling up visual and vision-language representation learning with noisy text supervision. In Pro-
ceedings of the 38th International Conference on Machine Learning, pages 4904–4916. PMLR, 2021 ↩︎ - Zhang, et al. mixup: Beyond Empirical Risk Minimization. In International Conference on Learning Repre-
sentations, 2018. ↩︎ - Young, et al. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2:67–78, 2014. ↩︎