
Introduction: A New Era
Financial markets are evolving faster than ever, demanding tools that can deliver insights at the speed and scale professionals need. At TD Securities (TDS), Generative AI (GenAI) is leading this transformation, empowering Sales & Trading teams to navigate complex data environments with greater efficiency and clarity. This post explores the TDS AI Virtual Assistant, a platform that leverages cutting-edge retrieval over both textual and tabular corpora, along with a dynamic user feedback mechanism for continuous refinement. These components combine to create a platform designed to be iterated upon, initially delivering key insights from both internal and external sources in a matter of seconds, improving the client experience and maintaining TDS’s foothold in an increasingly challenging landscape.
While this is a Layer 6 blog post focused on the modelling aspect, this project would not have been successful without invaluable contributions from the Front Office, TDS technology and AI teams, and the additional countless business and risk partners. Everybody rallied together to deliver a high-quality solution as part of a larger ecosystem.
From Siloed Data to Conversational Insight
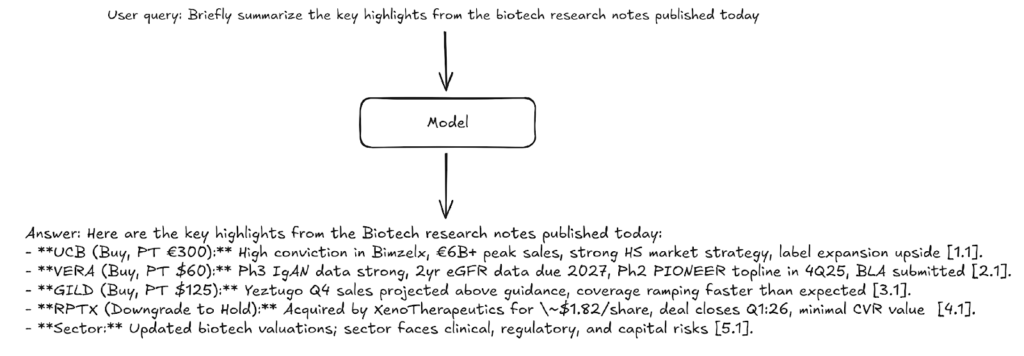
Traditionally, Front Office professionals have been burdened by fragmented data sources and manual search processes. Analysts would spend hours sifting through disparate databases and documents, resulting in slower decision making and limited productivity. The TDS AI Virtual Assistant, built on Azure OpenAI, overcomes these challenges by enabling users to ask questions in natural language from various sources. Whether retrieving the latest market data, summarizing research findings, or surfacing actionable insights, the system provides reliable answers instantly, complete with citations making them easily verifiable.
The Model
The TDS AI Virtual Assistant consists of two independent core features: a research chat powered by retrieval-augmented generation (RAG), and a market data chat that utilizes text-to-SQL technology. Together, these form a base platform to interact with both text and tabular data, and the user can switch between these two modes when asking a question. The initial implementation uses low-risk datasets such as the equity research notes published by TDS and public 13F filings. We describe the model’s components below.
The Research Chat
TD Securities has a highly renowned equity research division. Their team of over 90 highly qualified analysts specializes in conducting and publishing in-depth research on companies, industries, and financial markets. These analysts have deep knowledge and thought leadership in financial markets, industries, and companies, and are followed for their credibility and ability to make informed market predictions. Covering an impressive realm of approximately 1,300 publicly traded companies, TDS’s research analysts produce dozens of insightful articles daily. This wealth of knowledge and expertise constitutes an invaluable resource for traders, investors, and financial institutions.
The goal of the research chat is to harness this extensive knowledge base to provide insightful and actionable answers to front-office personnel. Specifically, the research chat employs Retrieval-Augmented Generation (RAG, as in NACO) alongside other advanced techniques to manage the vast and ever-evolving collection of documents. This approach ensures the retrieval of the most relevant documents for a user’s query and the formulation of accurate, verifiable responses.
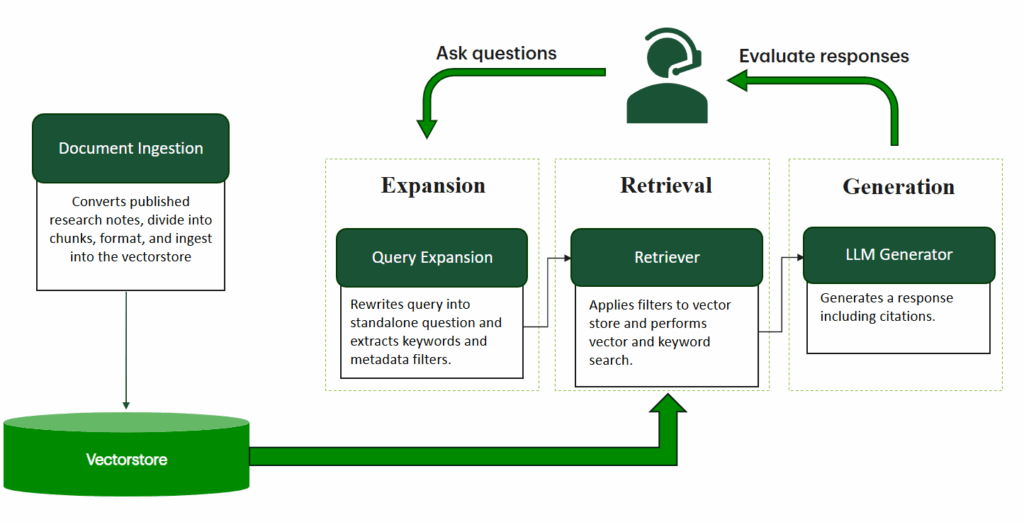
The main components of the research chat pipeline, which we detail below, are:
- Ingestion
- Retrieval
- Generation
Ingestion
The first step in the pipeline is the ingestion of research notes. This step is critical and stands apart from typical RAG applications due to the sheer volume of documents (over 10,000), their various formats, and dynamic nature. Research analysts publish new documents every working hour, and these documents must be processed and made accessible to the model within minutes of publication.
Published documents are first converted into a structured format, before being parsed and formatted in a way that enables efficient retrieval. Each document’s content is then partitioned into smaller chunks that are embedded and augmented with additional metadata (such as author, industry, publication date) from the original document. These chunks are then stored in a vector store for future retrieval. With the ingestion pipeline running continuously, newly published research notes are quickly parsed and ingested into the vector store, ensuring users can access the most up-to-date and relevant research data.
Retrieval with Advanced Filtering
Given the vast number of documents the model must process for each user query, identifying the most relevant ones poses a significant challenge. To address this, we apply advanced filtering on the vector store before retrieval—a critical step in pinpointing the right “needle in the haystack”. This filtering technique was refined through multiple iterations, incorporating insights from user interactions with the chatbot and feedback from core business users. The filtering process begins by reformulating the input text query, along with the chat history, into a standalone query. Predefined fields are then populated, and the relevant documents are filtered from the vector store for retrieval.
Generation
At inference time, the most relevant chunks from the retrieval process are reformatted and given as input to the model, along with the chat history and original user query. Refining the generation process was an important challenge for us, relying on continuous feedback from sales & trading pilot users to arrive at a solution that not only surfaced relevant insights as quickly as possible, but also spoke the same language as them. This process continues to this day and is elaborated on further below.
The Market Data Chat
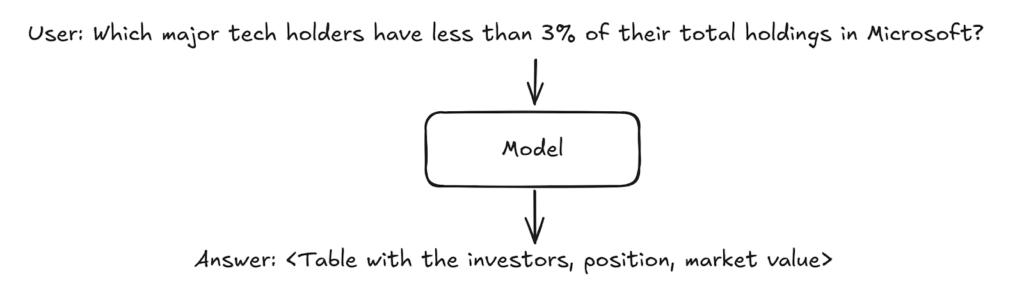
Now, we cover the market data chat, which uses a pipeline distinct from that of the research chat to retrieve data by converting plaintext queries into SQL. Text-to-SQL is a complex technical problem. The goal is to take a user query, and potentially a description of the available datasets, and output a syntactically correct SQL query that semantically captures the user’s query and can be executed against the available datasets to retrieve the requested data. The text-to-SQL component within the TDS AI Virtual Assistant is built to handle any type of tabular dataset, and is optimized to recognize industry-specific terminology and market entities. Depending on the user’s request, the market data chat can return results in either a tabular format or as a plot of the retrieved data. The market data chat can resolve complex queries (such as portfolio changes across quarters) in seconds and has significantly higher accuracy than out-of-the box models.
The main components of the text-to-SQL pipeline of the TDS AI Virtual Assistant are:
- Query rewriting and entity disambiguation
- Few-shot example retrieval
- SQL query generation and execution
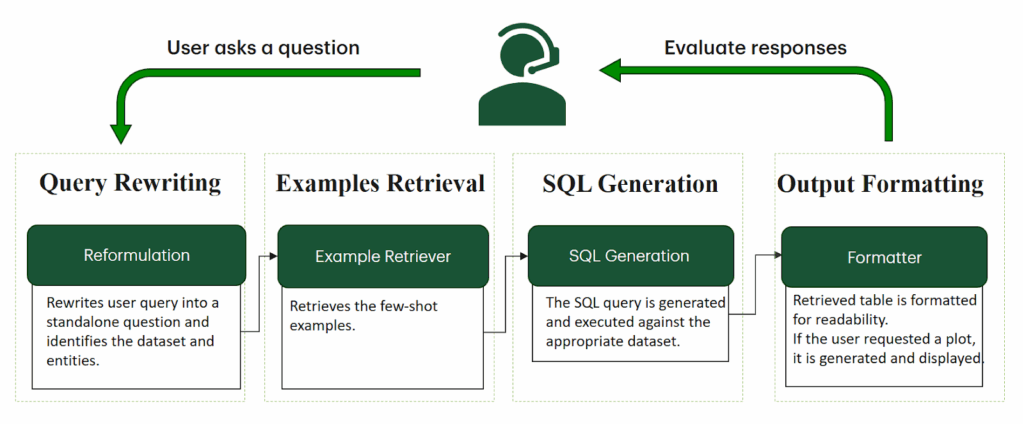
Query Rewriting and Entity Disambiguation
The system reformulates the user’s prompt and leverages the chat history to generate a clear and concise standalone question to be used by the model in the subsequent steps. Then, it uses sophisticated matching methods to identify the relevant entities such as tickers, investors, and sectors. This entity disambiguation step is crucial to ensure that the final SQL query accurately captures the relevant entities, even when the user’s prompt includes abbreviations or misspellings.
Dynamic Few-Shot Examples
To help the model generate accurate results, especially for complex queries, the pipeline includes dynamic few-shot examples. For a given user query, the model retrieves the most similar questions from a database of natural language queries and their corresponding SQL queries and adds them to the model’s input. This approach led to considerable improvements in model performance.
SQL Generation and Execution
Given the standalone query, few-shot examples, and the dataset schema, the model generates a SQL query and executes it against the relevant dataset, with additional steps to ensure the SQL query is syntactically correct and free of errors during execution.
Once the SQL query is executed, the retrieved data is formatted and displayed to the user as either a table or a plot. For tabular output, the data is simply formatted and presented, while for plots, the model generates a code snippet for the required visualization, executes it, and displays the resulting chart in the UI.
User Feedback as a Driver of Evolution
We now step back out of the specifics of the two chat pipelines and discuss how we integrate user feedback to continuously improve the TDS AI Virtual Assistant. Users provide feedback through thumbs-up or thumbs-down ratings and can add comments for further context. The Front Office frequently provides feedback to developers, working together to design targeted improvements. Frequently asked questions and novel usage patterns are identified and incorporated into subsequent model updates, ensuring the platform adapts to real user workflows. Several parameters can be adjusted, including prompt changes on the various components, adjustments to metadata stored along with the ingested documents, and the hyperparameters identifying lexical matches in the Text-to-SQL entity recognition component.
Importantly, when queries fall outside the model’s scope, the chatbot abstains and flags these cases for future enhancements. This feedback-driven methodology facilitates ongoing refinement and, above all, ensures the model’s actions are consistently aligned with the requirements of users and their clients rather than theoretical situations.
Transparency, Testing, and Governance
The TDS AI Virtual Assistant is built for explainability and rigorous oversight. In the research chat, the model’s responses contain citations to the relevant chunks that users can directly review in the UI and links to the original published document. In the market data chat, users can verify the generated SQL query, including the full names of the identified entities. Moreover, accuracy is continually tracked through human review, segmented by source and error type. The platform also operates within TD’s secure Azure Tenant, following robust risk, architecture, and monitoring protocols.
Conclusion: A Paradigm Shift and the Road Ahead
The TDS AI Virtual Assistant marks a paradigm shift in institutional investment research. By combining conversational AI, transparent analytics, and adaptive user feedback, the platform delivers faster insights, greater accuracy, and measurable productivity gains. As client needs evolve, TD Securities and Layer 6 will continue to explore how to expand the platform so that the future of investment research remains interactive, transparent, and relentlessly user driven. TD Securities is thus well-positioned to capitalize on this once-in-a-generation opportunity afforded by advancements in generative AI.
