This blog post is about our paper which was published as an oral paper at The 3rd Workshop on Vision Datasets Understanding at CVPR 2024. Please refer to the full paper for complete details. Our code is also publicly available here.
In the era of deep learning, one of the most pivotal factors in building high-performing machine learning models is the quality of the dataset used for training. However, gathering and annotating large datasets is a time-consuming and expensive process, particularly when dealing with tasks like object detection/localization. Object localization is particularly challenging due to its low tolerance for labeling noise, compared to other tasks in vision and language. For example, image classification requires only class labels (single or multi-class), while localization needs both accurate class labels and precise bounding boxes. Language models, on the other hand, can often handle mislabeled data better by leveraging contextual relationships, pre-trained embeddings, and fine-tuning to generalize over noisy labels. In contrast, noisy bounding box annotations in localization, even if slightly off, can severely impact object detection models, as bounding box precision directly affects metrics like Intersection over Union (IoU). This issue is further exacerbated by insufficient data or domain shifts, such as variations in camera viewpoints (e.g., surveillance vs. vehicle-mounted cameras), object size, and density. These factors amplify the challenges, making the quality of training data critically important for accurate object detection. This challenge becomes even more pronounced when there is a domain shift between the dataset you have (source) and the dataset you want to perform well on (target), meaning that your model could struggle to generalize to new data.
This is where the Classifier Guided Cluster Density Reduction (CCDR) framework steps in, our winning solution to the 2nd DataCV challenge at CVPR 2024. CCDR is designed to improve dataset selection from a larger pool of labeled images by identifying and curating the most relevant subset for object detection tasks. This blog post will introduce the challenge, break down the key components of CCDR, explain its technical aspects, and illustrate why it’s a game-changer for optimizing training datasets in machine learning.
The 2nd DataCV Challenge at CVPR 2024 presented a unique twist compared to traditional machine learning tasks. Unlike typical setups where the focus is solely on model architecture or hyperparameter tuning, this challenge emphasized the strategic selection of data—requiring participants to carefully curate a subset from a vast image pool to maximize model performance on a new, unseen dataset of real-world images from diverse regions. The difficulty lay in predicting the impact of each chosen sample on the model’s ability to generalize, simulating scenarios where annotation budgets are limited. This required a deep understanding of dataset diversity, balancing representation across regions without prior access to the target data, making it a complex and nuanced task unlike standard machine learning challenges. Our solution was among the top two entries amoing 57 teams who registered for the challenge.
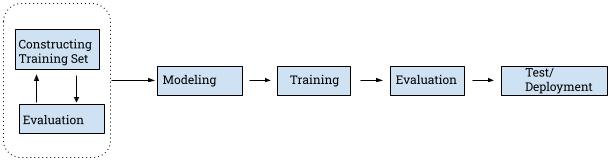
As shown in the diagram below, the challenge is to choose a subset from the source pool to form the training set, while the model parameters are fixed. This is unlike traditional machine learning tasks where the dataset is fixed and we tune the models instead.
The Data Dilemma: Source vs. Target
In supervised machine learning, the performance of models heavily relies on having a well-annotated, high-quality dataset. However, there’s often a mismatch between the data distribution in the dataset a model is trained on (source) and the data it needs to perform well on (target). This difference, known as a domain shift, can significantly affect the model’s ability to generalize.
For instance, in object detection tasks, source datasets might come from controlled environments (e.g., COCO or Cityscapes), while target datasets might contain footage from traffic cameras or driving videos captured from moving platforms (KITTI/BDD datasets). This discrepancy in data collection methods—different cameras, varying times of day, and distinct geographical locations—introduces challenges for machine learning models.
Traditional domain adaptation techniques can help mitigate this gap, but they often involve simultaneously training on both the source and target datasets. While effective, these methods can be resource-intensive and impractical in many cases. CCDR takes a different approach: it focuses on strategically selecting the most relevant subset of the source data to mirror the target distribution as closely as possible.
The CCDR Approach: A Two-Stage Framework

CCDR operates in two key stages:
1. Target-Specific Clustering and Ranking
In the first stage, CCDR performs clustering on the source dataset to identify groups of images that share similar features. It then ranks these clusters based on their similarity to the target dataset using a metric known as CLIP Maximum Mean Discrepancy (CMMD). This method compares the distribution of source clusters to that of the target dataset, ensuring that the selected clusters closely resemble the target distribution. Mathematically Mathematically, given two distributions P and Q , the MMD is defined as:
The advantage of MMD over FID is that it doesn’t assume multivariate Gaussian distribution distribution and is sample efficient(works with smaller sample size)
CCDR leverages Vision Transformer (ViT) latents, which are powerful representations of the images learned by a CLIP (Contrastive Language–Image Pre-training) model. By using this embedding space, CCDR ensures that both local and global image features are captured, making the clustering process highly accurate in selecting relevant images.
The goal in this stage is to identify clusters from the source dataset that resemble the target domain, without considering any constraints like dataset size or model budget. This step is all about maximizing the recall—retrieving as many relevant images as possible.
2. Cluster Density Reduction and Pruning
Once the relevant clusters are identified, the second stage of CCDR focuses on pruning. Not all images within a selected cluster are equally valuable, and some may be redundant or too similar to others. To tackle this, CCDR constructs a similarity graph based on the image embeddings and employs a classifier to guide the pruning process. The goal here is to reduce redundancy while ensuring that the final dataset is representative of the target domain.
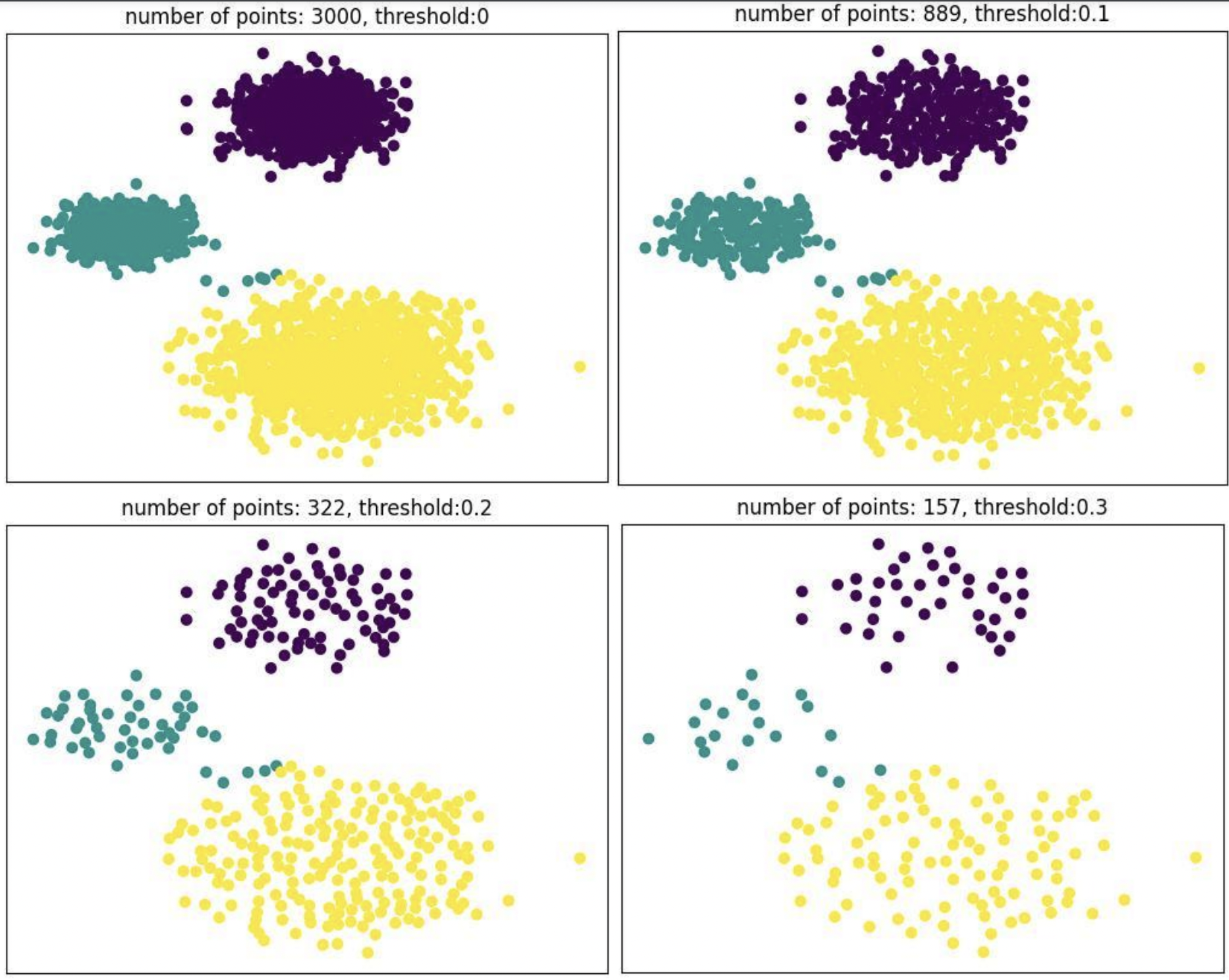
The classifier used in this stage is trained to approximate the Jensen-Shannon (JS) divergence between the source and target distributions. This allows CCDR to identify and retain the images most aligned with the target dataset, while eliminating redundant or less useful samples. As seen in the diagram above changing the threshold reduces the density of points but still spans the same space, thereby covering different unique cases that lead to optimized learning.
The classfier is trained to distinguish between target samples and source samples, by identifying important global features that are specific to the target set – such as camera viewpoint (e.g., surveillance vs. vehicle-mounted cameras), object density (e.g., the number of cars on a road), and etc – which are crucial for the object detection task.
The balance between diversity and relevance is key to the success of CCDR. By pruning clusters carefully, CCDR ensures that the final dataset is both compact and diverse, maximizing its effectiveness within the training budget. The algorithm is outlined below.

Why CCDR Excels: Technical Highlights
Now that we’ve covered the broad strokes of CCDR, let’s delve into some of its technical strengths:
- CMMD with ViT Latents: CCDR uses a powerful combination of CMMD and ViT latents to assess similarity between the source and target datasets. This ensures that the selected clusters truly reflect the target distribution, capturing both local details (e.g., object shapes) and global features (e.g., scene context).
- Graph-Based Pruning: By constructing a similarity graph, CCDR enables efficient pruning of redundant images. The use of a classifier for guiding this process ensures that the retained samples are the most relevant to the target dataset.
- Approximation of JS Divergence: The classifier is trained to approximate the JS divergence between the candidate and target distributions. This ensures that only the most aligned samples are retained, optimizing the dataset for better model performance.
- Scalable and Efficient: Unlike other domain adaptation methods that require simultaneous training on both source and target datasets, CCDR focuses solely on selecting the most relevant subset from the source. This makes it highly efficient, both in terms of computational resources and time.
Real-World Application: Object Detection in Region100
To validate the effectiveness of CCDR, we applied it to an object detection task using the Region100 dataset as part of the competition, which contains footage captured by 100 static cameras in various real-wotheirrld settings. The source datasets included ADE20K, BDD, Cityscapes, COCO, VOC, Detrac, and KITTI, totaling over 170,000 images.
The goal was to select a subset of the source dataset (8000 images) to train a detection model on Region100. CCDR was able to significantly outperform baseline methods, achieving a mean Average Precision (mAP) score of 22.2%, compared to just 13.6% with random dataset selection. Even when compared to a strong baseline like SnP(SOTA), CCDR showed very strong improvements(over 4 points).
Why CCDR Matters: Broader Implications
Beyond object detection, CCDR’s principles can be applied to a wide range of machine learning tasks that involve dataset selection. Whether it’s semantic segmentation, image retrieval, or transfer learning, CCDR provides a framework for optimizing training datasets in a way that balances relevance, diversity, and efficiency.
Moreover, CCDR addresses a growing challenge in AI: the need for models to generalize well across different domains. As AI systems become more integrated into real-world applications—ranging from autonomous vehicles to medical diagnostics—this ability to generalize is crucial. CCDR provides a scalable, effective solution for tackling domain shifts by ensuring that training datasets are well-aligned with the target environment.
Conclusion
The Classifier Guided Cluster Density Reduction (CCDR) framework offers a robust solution to one of the biggest challenges in machine learning: selecting the right data. Its two-stage approach—combining clustering with careful pruning—ensures that only the most relevant and diverse samples are retained, making it highly effective for optimizing training datasets in tasks like object detection.
By improving dataset selection, CCDR not only enhances model performance but also reduces the computational costs associated with training large models on unnecessary data. In a world where data is becoming increasingly complex and diverse, methods like CCDR are essential for building efficient, scalable, and high-performing AI systems.
For those interested in experimenting with CCDR, we have made our code publicly available on GitHub. Give it a try and see how it can optimize your dataset for better model performance!